動的ワークロード管理の評価ポイント
動的ワークロード管理の評価ポイント
次にワークロード管理を行う上で考慮すべきポイントを解説する。動的ワークロード管理は、運用をしていく中で刻々と変化する仮想サーバの負荷(ワー クロード)をいかに瞬時に把握し、適切なリソースの配分を行うための情報や操作ができるかということを考慮する必要がある。
監視可能項目
動的ワークロード管理を行うため、各仮想サーバにどのくらいの負荷がかかっているかを把握でき なければならない。そのためには、まず仮想サーバ内のリソースが、現在どのように、どれくらい利用されているのかを把握することが必要である。具体的に は、仮想サーバのCPUの利用率、仮想サーバに割り当てられているメモリの利用率、仮想サーバに割り与えられているネットワーク帯域などである。
基本的にはCPU、メモリ、ネットワーク帯域の利用率がリアルタイムに監視できれば十分であるが、仮想サーバ上で稼動しているシステムによっては、 単純なCPUネック、メモリネックということだけではないこともある。そのため作りこみが発生するが独自の監視項目を作成できる製品もある。たとえば Syslogの中身や、アプリケーション固有のログなどを監視項目として設定することが可能なものである。
設定可能なトリガ
上記で述べた監視可能な項目(CPU、メモリ、ネットワーク帯域)の値を収集し、リソースの再配分を行うためのロジックを動作させるための閾値を設定し、その閾値を超えたときにリソースの再配分を行う。
閾値の設定は、上記のCPU利用率、メモリ利用量の閾値を%で指定するような単純なものから、さまざまな監視項目を組み合わせることでより上位の閾 値を設定できるものもある。より上位の閾値の例としては、仮想サーバで処理できるスループットやレスポンスタイムを閾値とするなどである。
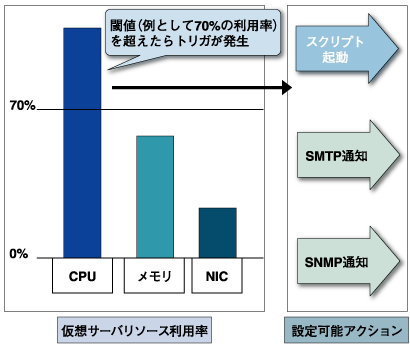
図3:トリガ、設定可能アクション
再配分可能リソース
監視可能項目で監視していた値が閾値を超えたときに、リソース配分を変更する。このときに変更できるリソースの種類によって、より多くの状況に対してきめ細かなワークロード管理ができる。
最低限仮想サーバに割り当てられている物理CPUの配分の変更はできる必要があるが、他にもメモリ、ディスクI/O帯域、ネットワーク帯域の配分を変更できるものもある。
設定可能アクション
値を監視し、値がある閾値を超えたときに、仮想サーバのリソースの変更や他のシステムへの通知などを行う。この時の仮想サーバから外部への通知方法により、他のシステムとの運用監視の統合や連携・拡張のしやすさが異なる。
単純なものでは再配分可能リソースで述べたCPU利用率、メモリ使用量などの閾値を超えたら、それぞれ不足したリソースを確保するように設定を変更する機能のみを持つ。
製品によっては、CPU、メモリの増減以外の動作を行うためスクリプトを起動することのできるものや、外部のプログラムを起動できるものもある。ま た、システム管理者に動作状況を知らせる方法としてSMTPを用いてメール送信するものや、他の監視ツールと連携するためにSNMPに対応しているツール もある。
今後の動向
これまで3回に渡り、サーバ仮想化技術を中心に現状の技術とその評価ポイントについて解説して きた。ここでは今後の技術の動向について解説する。これら技術は第1回で解説したとおりユーティリティコンピューティングを形成するための要素技術であ る。したがって今後はこのユーティリティコンピューティングへの達成に向けて技術は進化していくと思われる。例えば、ユーティリティコンピューティングの 適用として最も注目されているデータセンターへ適用することを考えてみよう。
大規模なデータセンターには何百・何千という物理サーバが存在しているため、サーバを仮想化し運用管理負荷を削減することに大きな意義があるだろ う。しかし、実際には既存の複数の異なるベンダーのハードウェアがいくつも存在するため、これら異機種サーバの上で統一的に管理できる仮想サーバおよび ワークロード製品が必要となってくるだろう。
また刻々と変化していく仮想サーバの負荷に応じたリソースの自動配分を、自律的に行えるようにし、さらに人間の介在する余地を減らしていくような運用の効率化を目指した技術も進化していくと思われる。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
