【CNDW2025】ABEMAの広告基盤を高速化した分散カウンターの実装とスケーラビリティ戦略
「ABEMAのCM配信を支えるスケーラブルな分散カウンターの実装」と題したセッションを紹介する。
2月9日 6:00
CloudNative Days Winter 2025では、「ABEMAのCM配信を支えるスケーラブルな分散カウンターの実装」をテーマに、株式会社CyberAgent/株式会社AbemaTVのソフトウェアエンジニア戸田 朋花氏が、急増する広告リクエストに対応するための設計思想と実装の全容を紹介した。生放送で数十万RPS(Requests Per Second)規模のスパイクが発生する環境下で、広告配信をリアルタイムに制御するには、膨大なイベントを正確かつ高速にカウントできる基盤が不可欠である。その基盤を支える二層構造の設計から、Google Cloud上で実現した分散カウンター、そしてさらなるスケーラビリティのために採用した分散データ構造までを整理して解説する。
ABEMAのCM配信とリアルタイム計測の課題
ABEMAは「新しい未来のテレビ」として多彩な番組を24時間配信し、開局以来ユーザー数が増え続ける成長中のプロダクトである。戸田氏は「ABEMAは開局してから現在までユーザー数が増加している成長中のサービスです」と語り、サービスの拡大にともなって広告配信基盤にも高い拡張性が求められている現状を説明した。
ABEMAの広告配信は、ユーザーの視聴履歴や属性などのデータを用いたパーソナライズが可能であり、ターゲティングやフリークエンシーコントロールなど複数の条件を参照して配信内容が決定される。広告は設定された目標インプレッション数に近づけるように制御されるが、カウント処理が遅延すると実績値が正確に反映されず、目標を超えて配信してしまう危険がある。
とりわけ生放送番組では、CMに切り替わる瞬間に視聴計測リクエストが一斉に発生するため、負荷が極端に高まる。スライドでは、あるサービスにおいてRPSが1分間で約200倍に跳ね上がるスパイクが『日常的に』発生するケースが紹介されている。戸田氏も「こうした瞬間的な負荷にも耐えつつ、リアルタイムにカウントし続ける必要があります」と述べ、スパイクが特例ではなく一般的に起こり得る問題であることを示した。
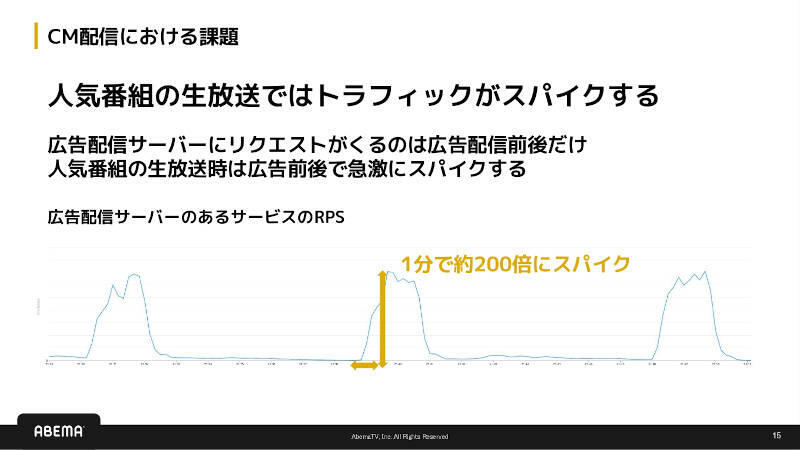
CM配信における課題 人気番組の生放送ではトラフィックがスパイクする
また計測対象となるイベントはCMの開始・完了、視聴インプレッションなど複数種類が存在し、それぞれが高頻度で発生するため、システムには多様なイベントを漏れなく高速に受け付ける能力が求められる。ユーザーごとの視聴状況や広告予算は刻々と更新されるため、これらをニアリアルタイムに把握できるスケーラブルなカウンターの存在が不可欠である。
こうした要件を満たすため、ABEMAではKubernetes上のGo製アプリケーションとValkey Cluster、Cloud Spanner、BigQueryなどを組み合わせ、分散カウンター基盤を構築している。
値の正確性とスループットを両立するカウンター設計
ABEMAの分散カウンターは、リアルタイム性と正確性を両立させるための二層構造である。まず高速に書き込むことを目的としたスピードレイヤーが、クライアントからのイベントを即座に受け付け、ホットストレージへ反映する。「まずは速く書き込み、あとで補正するという構成にしています」と戸田氏が語るように、この段階では正確性よりも『取りこぼさないこと』を優先している。
一方、正確な集計値を得るために存在するのがバッチレイヤーである。スピードレイヤーと同じイベントがイベントログにも保存され、補正バッチによって重複排除(At-least-once配信への対策)と集計が行われる。補正後の値はホットストレージおよびコールドストレージに反映され、最新値や長期間の集計値を用途に応じて使い分ける構造となっている。
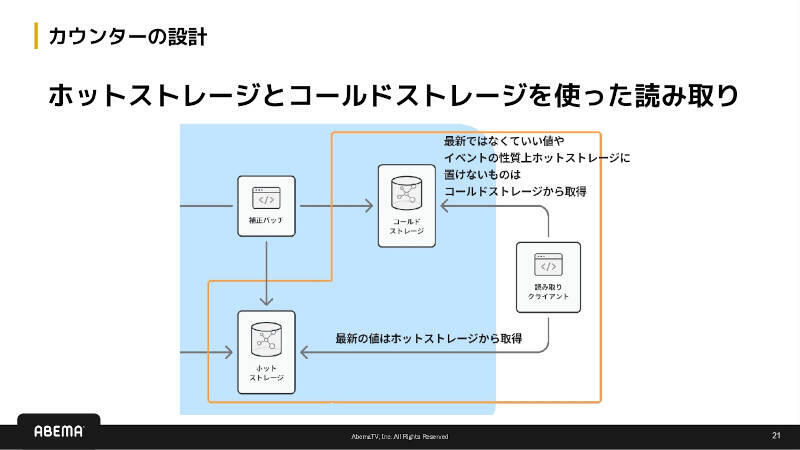
カウンターの設計 ホットストレージとコールドストレージを使った読み取り
この二層構造により、ABEMAは「高速な書き込み」と「正確な集計」という二つの要件を満たすカウンター基盤を実現している。次章では、この二層構造を支える具体的なアーキテクチャとして、Pub/Sub(Publish/Subscribe)によるイベント取り込みからValkeyでの高速書き込み、BigQuery・Spannerによる集計値管理まで、Google Cloud上での実装を詳しく見ていく。
Google Cloud上に構築した分散カウンター基盤
ABEMAは、前章で示した二層構造をGoogle Cloud上で構築している。イベントストリームにはPub/Subを用い、複数サブスクリプションを利用して用途別にイベントをファンアウトすることで、高トラフィック時でも安定して取り込めるようにしている。
ホットストレージにはMemorystore for Valkey Clusterを採用し、キーのハッシュ値に基づくシャーディングによって水平スケールを実現している。戸田氏は「マネージドでクラスタを拡張しやすい点が使いやすさにつながっています」と語っている。
イベントストレージにはBigQueryを使用し、CountAt(計測時刻)でのパーティショニング、カウンターキーでのクラスタリングを併用することで、補正バッチで必要となるスキャン範囲を大幅に削減している。コールドストレージにはCloud Spannerを用い、プライマリーキー順の物理配置によって時間範囲クエリを効率化しつつ、小規模構成でもCloud SQLより低コストで始められる点も評価されている。コンピュート部分はGKEに構築され、ライター処理は常時稼働するPodが担当し、補正バッチはCronJobとして定期実行される。
さらにABEMAでは、用途に応じて3種類のカウンターを使い分けている。通常カウンターはString型でINCRBY/GETを利用するシンプルな形式。時系列カウンターはHash型で書き込み、確定後にSorted Setへ変換する方式で、変換にはValkey Functionsを活用して高速化している。またユニーク数の推定が必要な用途ではHyperLogLogを使用し、メモリ効率の高いユニークカウンターとして運用している。

さまざまな種類のカウンターの実装 時系列カウンター
このようにABEMAは、Google CloudのマネージドサービスとValkey Clusterを組み合わせることで、リアルタイム性・正確性・スケーラビリティを兼ね備えた具体的な分散カウンター基盤を実現している。
さらなるスループット向上と分散データ構造の導入
ABEMAでは分散カウンター基盤を運用する中で、さらなるスループット向上に向けた課題として、Valkeyが持つ「同一キーへの書き込みは単一ノードに集中する」という特性が顕在化していた。同じキーに対するINCR操作はシャーディングされず、どれだけクラスタを増やしても単一ノードがボトルネックとなる。戸田氏は「単一キーにアクセスが集中すると、どうしてもスケールの壁が生まれます」と語り、長期的な負荷増大を見据えるうえでこの制約が避けられない問題であることを示した。
この課題に対し、ABEMAが採用したのがキーを複数に分割し、各パーティションへ独立して書き込む方式である。しかし単純な分割では、最終的に正確な値を得るための整合性維持が難しい。そこで活用されたのがCRDT(Conflict-free Replicated Data Type)の一種であるGCounterである。GCounterは複数ノードで独立に更新を行っても、各パーティションの値を単純に加算するだけで最終値として整合するという特性を持つ。この仕組みにより、更新順序や到達順に依存せず、スケールと整合性を同時に成立させられる。
ABEMAではこのGCounterをValkey上で実現している。具体的には、ValkeyのHash型を用い、カウンターキーにパーティションIDをサフィックスとして付与して複数ノードへ分散書き込みを行う方式である。読み取り時には各パーティションの値を合算することで、論理的には一つのカウンターとして扱える。この構造により、Valkeyの単一キー性能を超えてクラスタ全体のスループットを引き出すことが可能となった。
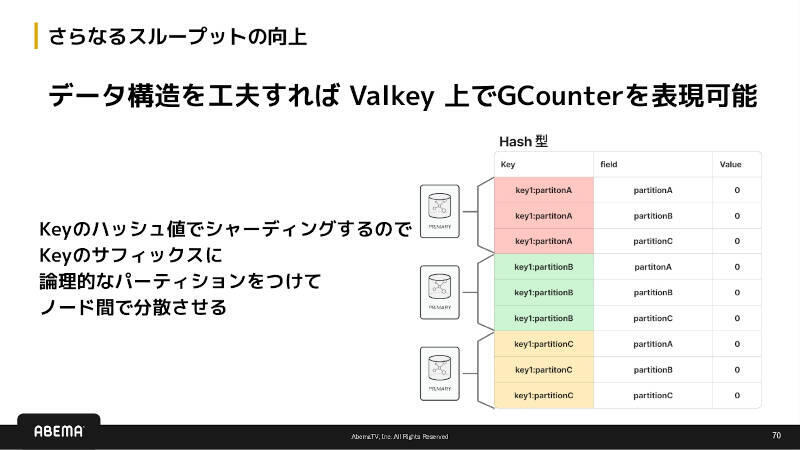
さらなるスループットの向上
GCounterの導入は、広告配信のさらなる成長に耐えられる基盤を整えるための長期的なアプローチでもある。戸田氏は「長期的に負荷が増えても耐えられる仕組みを作りたいと考えています」と語り、CRDTを活用した分散データ構造の採用が今後の拡張において重要な役割を担うと強調した。
こうした取り組みにより、ABEMAの分散カウンター基盤は、高スループット・リアルタイム性・正確性・スケーラビリティを兼ね備えつつ、将来的なトラフィック増加にも適応できる構造へと進化している。今後もCRDTをはじめとした分散データ構造を取り入れ、広告配信の高度化に対応できる基盤へと発展していくことが期待される。
- この記事のキーワード
この記事をシェアしてください
関連記事
【CNDW2025】Dev ContainersとSkaffoldで実現するクラウドネイティブ開発環境
3月24日 6:00
【CNDW2025】プロダクト急増に備える基盤刷新 ーウェルスナビがECSからEKSへの移行で得た知見とは
1月15日 6:30
【CNDW2025】AppleのContainerization Frameworkから学ぶコンテナ技術の仕組みとその裏側
1月7日 6:00
【CNDW2024】金融システムにおけるクラウドネイティブ化を実現するEKSの最前線
2025年2月18日 6:00
【CNDW2025】日本初のクラウド勘定系を実現した次世代バンキングシステムの設計と運用
2025年12月19日 6:00
【CNDW2024】クラウドネイティブを支えるeBPFの実装と技術的背景を深掘り
2025年3月27日 6:00
バックナンバー
この記事の筆者
筆者の人気記事
【CNDS2025】国産クラウドが目指すCloudNativeの未来 さくらのクラウドの進化と展望
2025年6月13日 6:01
NoSQLとNewSQLの技術革新、マルチテナンシーの実現と高いスケーラビリティを提供
2024年8月19日 6:00
アプリケーションをモジュラーモノリスとして記述し、容易にマイクロサービスとしてデプロイできるフレームワーク「Service Weaver」
2024年7月23日 6:30
【CNDW2025】日本初のクラウド勘定系を実現した次世代バンキングシステムの設計と運用
2025年12月19日 6:00
次世代クラウド基盤「Wasm」の可能性と課題を探る
2024年11月5日 9:06
【CNDW2024】東京ガスの内製開発チームが挑むKubernetesの未来
2025年3月10日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
