クラスターを詳細監視する「Container Insights」のセットアップと有効化【後編】
第22回の今回は、前回に引き続きクラスターを詳細監視するCloudWatchの機能「Container Insights」のダッシュボード活用と監視のベストプラクティスについて解説します。
3月31日 6:30
はじめに
第20回では、CloudWatchアラームを使った自動通知の仕組みを学びました。CPU使用率、ネットワークトラフィック、Auto Scaling Groupの最大サイズ検知など基本的なアラームを設定し、問題を早期に検知できるようになりました。
そこではメモリ使用率やディスク使用率のアラームについても触れましたが、「Container Insightsの有効化が必要」と簡単に説明するにとどめました。そこで前回では「Container Insightsとは何か」「どのように有効化するのか」を詳しく解説しました。「Amazon CloudWatch Observability EKS add-on」をインストールし、ノード、Pod、コンテナレベルの詳細なメトリクスを収集できるようになりました。
今回はContainer Insightsの具体的な使い方を解説します。Container Insightsダッシュボードの見方、監視すべき重要なメトリクス、トラブルシューティングの方法、そしてベストプラクティスを紹介します。セットアップは完了しているので、実際にどう活用するかを学んでいきましょう。
Container Insightsダッシュボードの確認
前回では、Amazon CloudWatch Observability EKS add-onをインストールし、Container Insightsを有効化しました。CloudWatch Logsでロググループが作成されていることを確認し、メトリクス収集が開始されたところまで進めました。
今回は、収集されたメトリクスをどのように確認し、活用するかを見ていきます。Container Insightsが有効化されると、CloudWatchコンソールに専用のダッシュボードが表示されます。
ダッシュボードへのアクセス
- CloudWatchコンソールを開く
- 左側メニューから「Container Insights」を選択
Container Insightsダッシュボードが表示されます。
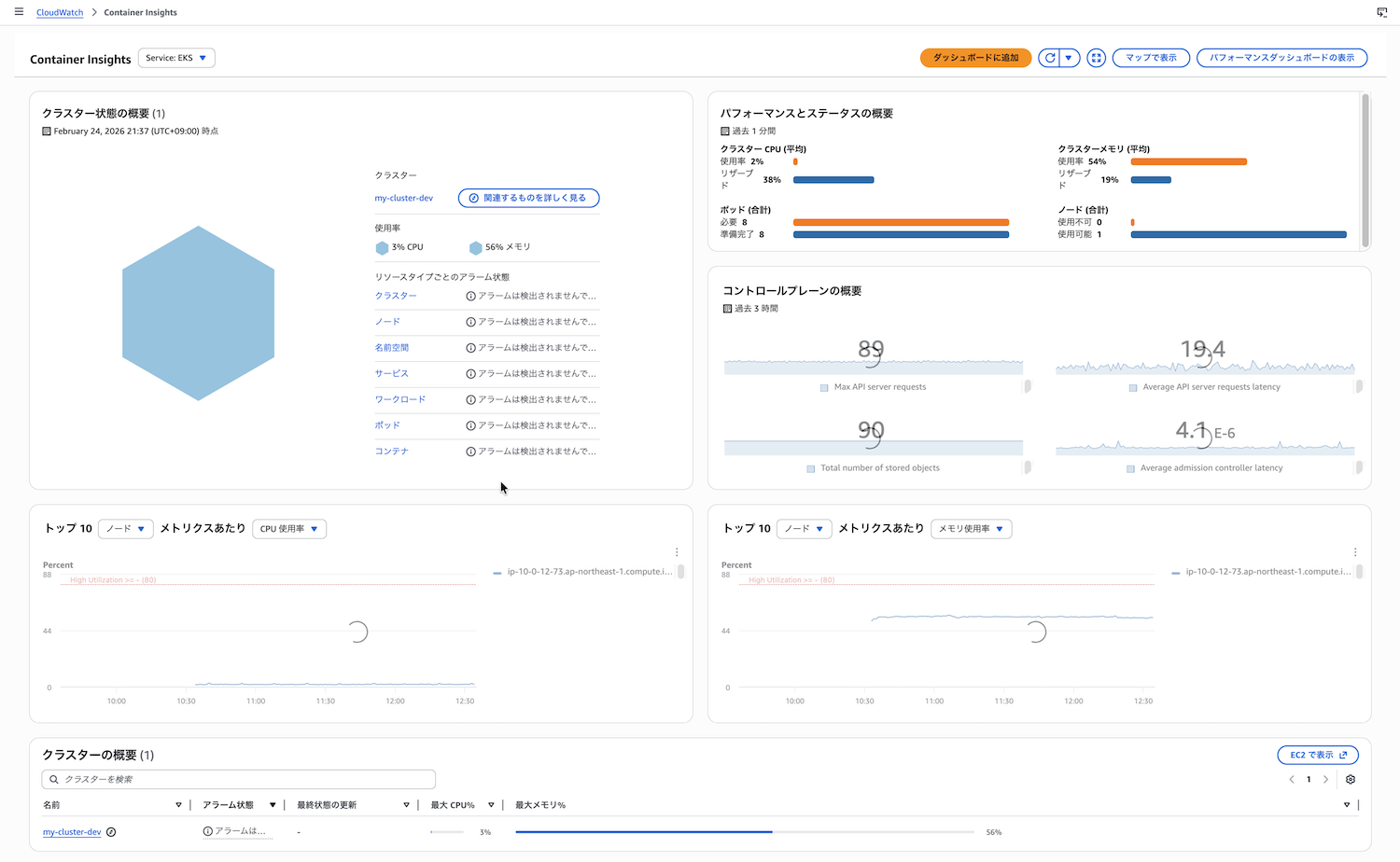
Container Insightsで表示できる情報
Container Insightsでは、以下の2つの表示方法でメトリクスを確認できます。ダッシュボード上部の「パフォーマンスダッシュボードの表示」または「マップで表示」ボタンで表示を切り替えられます。詳細な使い方は公式ドキュメントを参照してください。
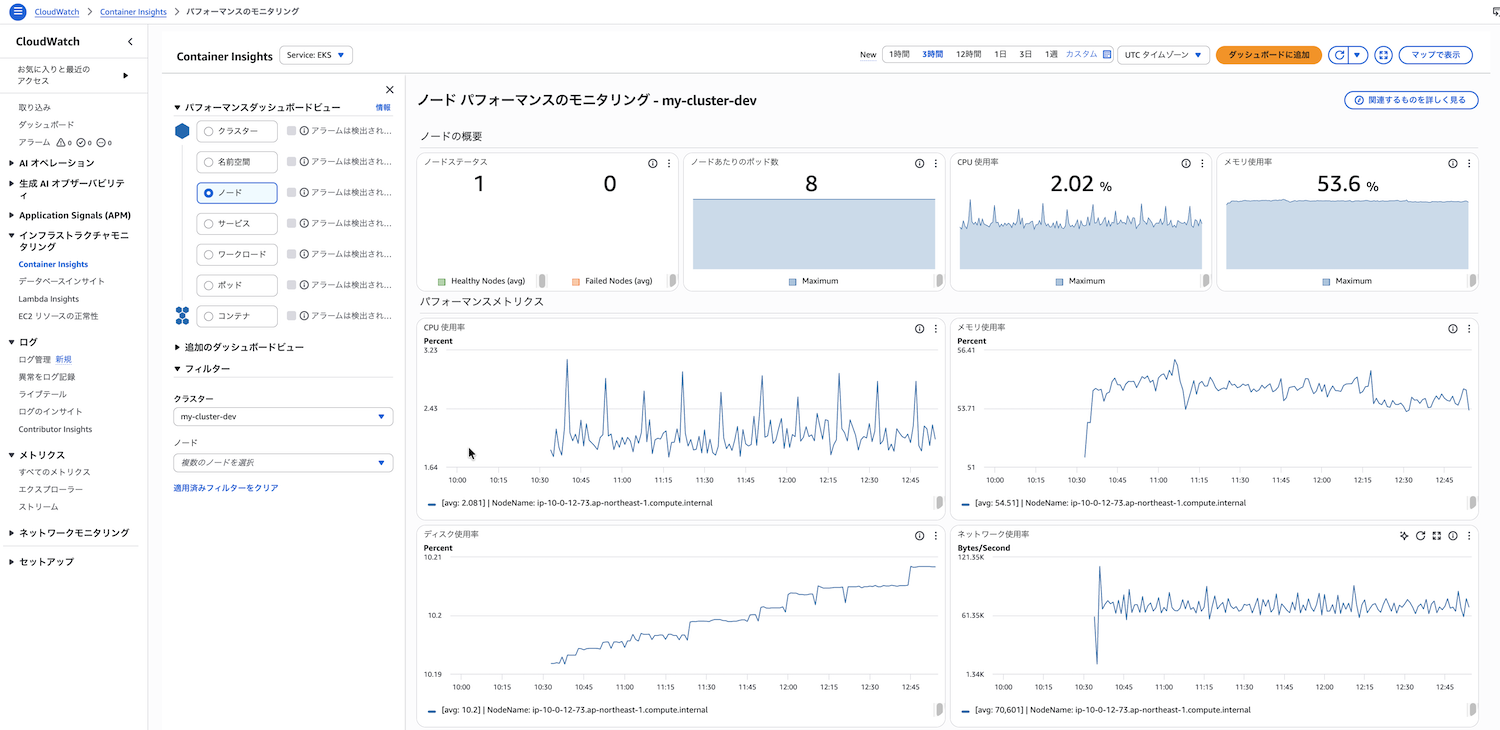
パフォーマンスダッシュボードの表示
左側のサイドバーから、表示したいリソースタイプを選択できます。
- クラスター: クラスター全体のメトリクス(ノード数、Pod数、CPU使用率、メモリ使用率など)
- 名前空間: Namespaceごとのリソース使用状況
- ノード: ノードごとの詳細メトリクス(CPU、メモリ、ディスク使用率、稼働中のPod一覧など)
- サービス: Serviceごとのメトリクス
- ワークロード: ワークロードごとのメトリクス
- ポッド: Podごとの詳細メトリクス(CPU、メモリ使用率、コンテナ再起動回数など)
- コンテナ: コンテナごとの詳細メトリクス
各リソースタイプを選択すると、CPU使用率やメモリ使用率などのメトリクスが時系列グラフで表示されます。また、画面下部にはリソース使用率の高い順にソートされたテーブルが表示され、どのリソースが最もリソースを消費しているかを素早く特定できます。
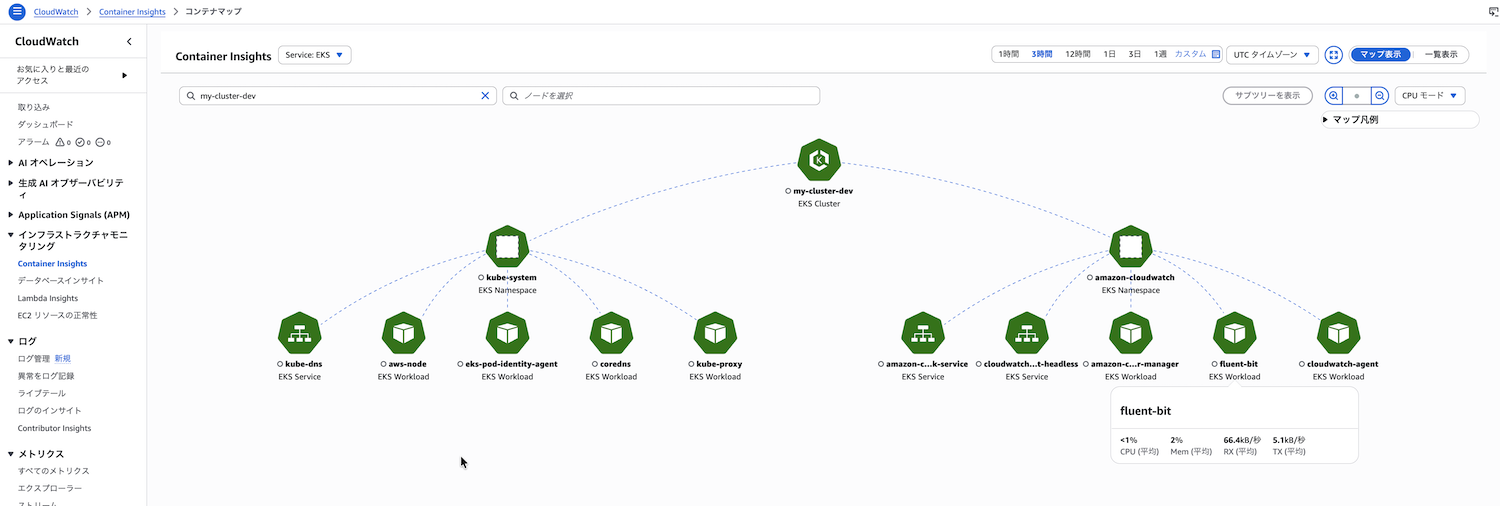
マップで表示
上部の「マップで表示」ボタンをクリックすると、リソースをビジュアルマップで表示できます。
- リソースにカーソルを合わせると基本的なメトリクスが表示される
- リソースを選択すると詳細なグラフが表示される
- クラスター全体のリソースの健全性を一目で把握できる
マップビューは、複数のリソース間の関係性を視覚的に理解するのに便利です。
監視すべき重要なメトリクス
Container Insightsで収集されるメトリクスの中で、特に監視すべき項目を紹介します。
ノードメモリ使用率(node_memory_utilization)
ノード全体のメモリ使用率を示します。第20回で設定したアラームのしきい値(80%)を基準にメモリ使用率を監視します。ノードのメモリ使用率が高まると、以下の問題が発生します。
- メモリ不足により新しいPodをノードに配置できなくなる
- ノードのメモリが枯渇すると、優先度の低いPodから順にOOMKillerによって強制終了される
- メモリ不足が深刻な場合、ノード自体が
NotReady 状態になり、すべてのPodが退避される可能性がある
ノードレベルのメモリ使用率を監視することでノード全体のリソース不足を早期に検知し、ノードの追加やPodのリソース制限の見直しを行うことができます。
確認すべきポイント
以下の点を定期的に確認します。
- ノード全体のメモリ使用率が80%を超えていないか
- 特定のノードだけメモリ使用率が高くないか(不均等な負荷分散)
- メモリ使用率が時間とともに増加していないか(メモリリーク)
問題が見つかった場合の対応
ノードのメモリ使用率が高い場合、以下の手順で調査と対応を行います。まず、どのPodがメモリを消費しているかを確認します。
# ノード上のPodをメモリ使用量順にソート
$ kubectl top pods --all-namespaces --sort-by=memory次に、メモリ使用量が多いPodの詳細を確認します。
# Podの詳細情報とリソース制限を確認
$ kubectl describe pod <pod-name> -n <namespace>対応策としては以下が考えられます。
- Auto Scaling Groupの最大サイズを増やし、ノードを追加する
- メモリ消費が多いPodのリソース制限(limits)を必要に応じて増やす
- 不要なPodを削除してメモリを確保する
- Podの水平スケーリング設定を見直し、負荷を分散させる
ノードディスク使用率(node_filesystem_utilization)
ノードのディスク使用率を示します。ノードのディスク使用率が高まると、以下の問題が発生します。
- コンテナイメージのダウンロードやPodの起動に必要なディスク容量が確保できず、Podが
ImagePullBackOffやPending状態になる - アプリケーションログやコンテナログが書き込めなくなり、障害調査が困難になる
- ディスク容量不足が深刻な場合、ノードが
DiskPressure状態になり、Podが退避される
ノードのディスク使用率を監視することでディスク容量不足を早期に検知し、古いコンテナイメージの削除やログローテーションの設定見直し、ディスクサイズの拡張を行うことができます。
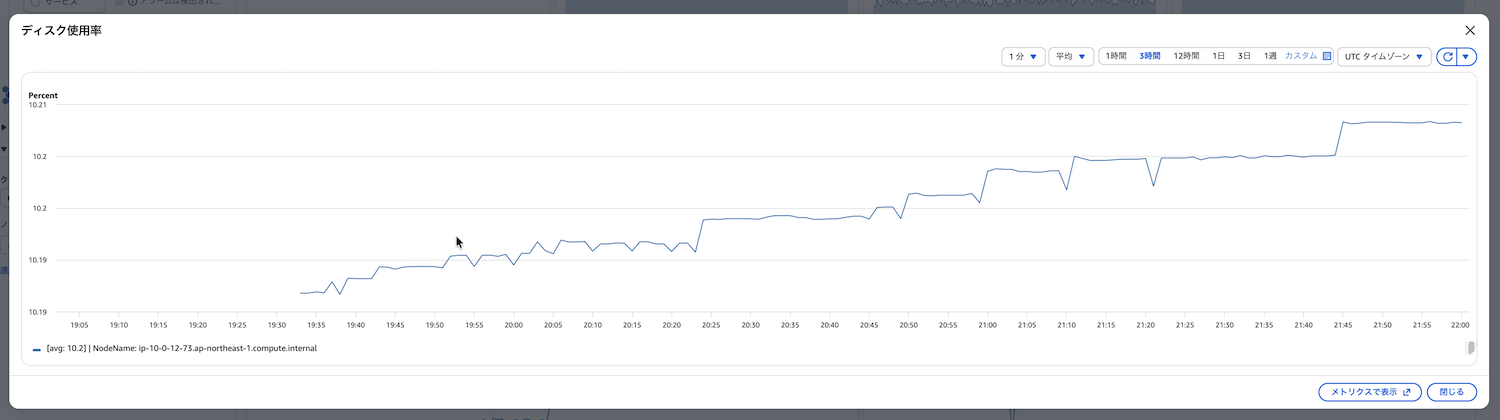
以下の点を定期的に確認します。
- ノードのディスク使用率が80%を超えていないか
- ログファイルが肥大化していないか
- コンテナイメージのキャッシュが蓄積していないか
問題が見つかった場合の対応
ノードのディスク使用率が高い場合、以下の手順で調査と対応を行います。まず、ノードの詳細情報とディスク使用状況を確認します。
# ノードの詳細情報を確認
$ kubectl describe node <node-name>
# ノードのディスク使用状況を詳細に調査(kubectl debugを使用)
# 詳細: https://kubernetes.io/docs/tasks/debug/debug-application/debug-running-pod/#node-shell-session
$ kubectl debug node/<node-name> -it --image=ubuntu -- chroot /host bash
# デバッグコンテナ内で以下を実行
$ df -h
$ crictl images【注意】EKSではKubernetes 1.24以降、コンテナランタイムとしてcontainerdが使用されているため、dockerコマンドではなくcrictlコマンドを使用します。
対応策としては以下が考えられます。
- 古いコンテナイメージを削除(ノード上で
crictl rmiを実行) - ログローテーションの設定を見直す
- ディスクサイズを増やす(EBSボリュームのサイズ変更)
- 不要なPodを削除してディスク容量を確保する
Podのコンテナ再起動回数(pod_number_of_container_restarts)
Podのコンテナが再起動された回数を示します。コンテナの再起動回数が増加すると、以下の問題が発生します。
- コンテナが再起動するたびに処理中のリクエストが失敗し、ユーザーに影響が出る
- 短時間に何度も再起動を繰り返すとKubernetesが再起動の間隔を徐々に延ばし、Podが正常に起動できなくなる(
CrashLoopBackOff状態) - 再起動の原因(メモリ不足、ヘルスチェック失敗、アプリケーションバグなど)を特定せずに放置すると問題が悪化する
コンテナの再起動回数を監視することでアプリケーションの問題を早期に検知し、根本原因を特定して修正できます。
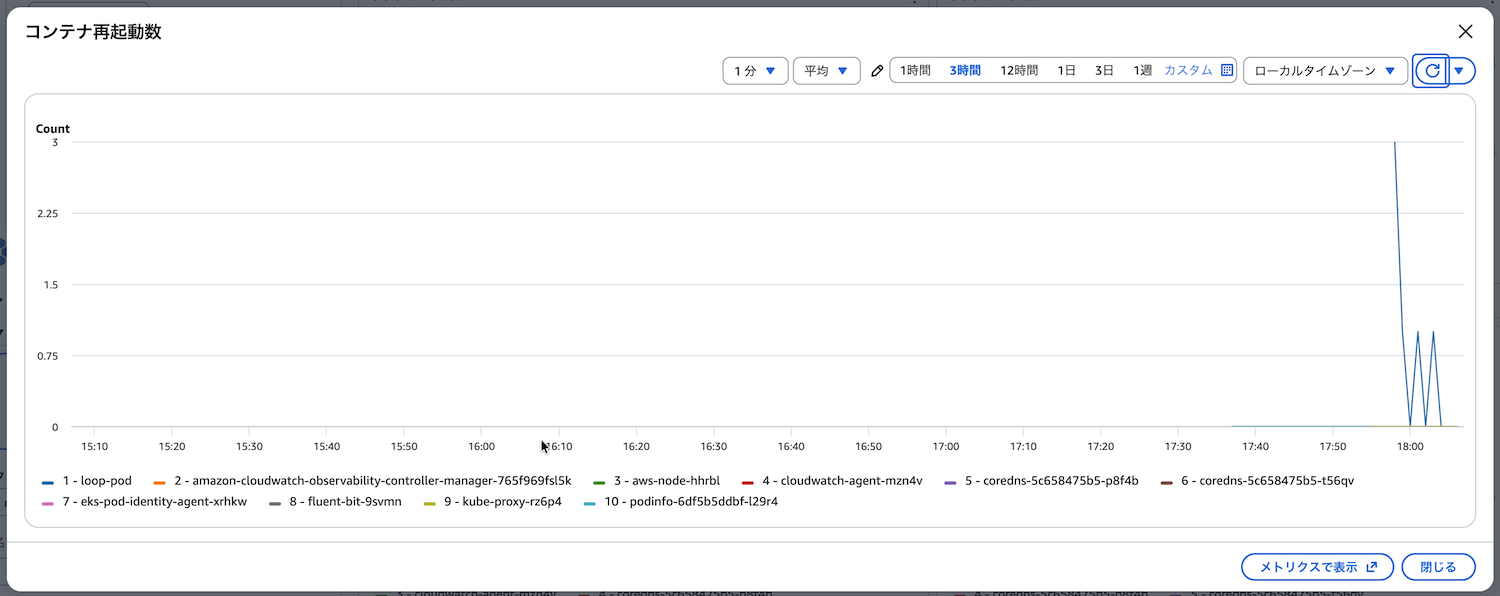
確認すべきポイント
以下の点を定期的に確認します。
- 特定のPodだけ再起動が多くないか
- 再起動のタイミングにパターンがあるか(メモリ不足、ヘルスチェック失敗など)
- 再起動の原因をPodのイベントやログから特定できるか
Podの再起動が頻発している場合、以下の手順で調査と対応を行います。まず、Podのイベント履歴を確認し、再起動の原因を特定します。
# Podのイベント履歴を確認(再起動の原因が記載されている)
$ kubectl describe pod <pod-name> -n <namespace> | grep -A 10 Events
# Podのログを確認
$ kubectl logs <pod-name> -n <namespace>
# 前回のコンテナのログを確認(再起動前のログ)
$ kubectl logs <pod-name> -n <namespace> --previous次に、PodのメモリやCPU使用状況を確認します。
# Podのメモリ・CPU使用状況をリアルタイムで確認
$ kubectl top pod <pod-name> -n <namespace>対応策としては以下が考えられます。
- メモリ不足が原因の場合、Podのリソース制限(limits)を増やす
- ヘルスチェック失敗が原因の場合、ヘルスチェックの設定(タイムアウト、間隔など)を見直す
- アプリケーションのバグが原因の場合、ログを分析してバグを修正する
- OOMKillerによる強制終了の場合、メモリリークがないか調査する
ポッドメモリ使用率(ポッド制限超過)(pod_memory_utilization_over_pod_limit)
Podのメモリ使用率がPodに設定されたメモリ制限(limit)に対してどの程度の割合かを示します。Podがメモリ制限を超過するとOOMKiller(Out Of Memory Killer)によりPodが強制終了されます。これにより以下の問題が発生します。
- Podが再起動され処理中のリクエストが失敗する
- 頻繁に再起動が発生するとアプリケーションの可用性が低下する
CrashLoopBackOff状態になり、Podが正常に起動できなくなる可能性がある
このメトリクスを監視することで、OOMKillerによる強制終了が発生する前にメモリ制限の見直しやアプリケーションの最適化を行うことができます。
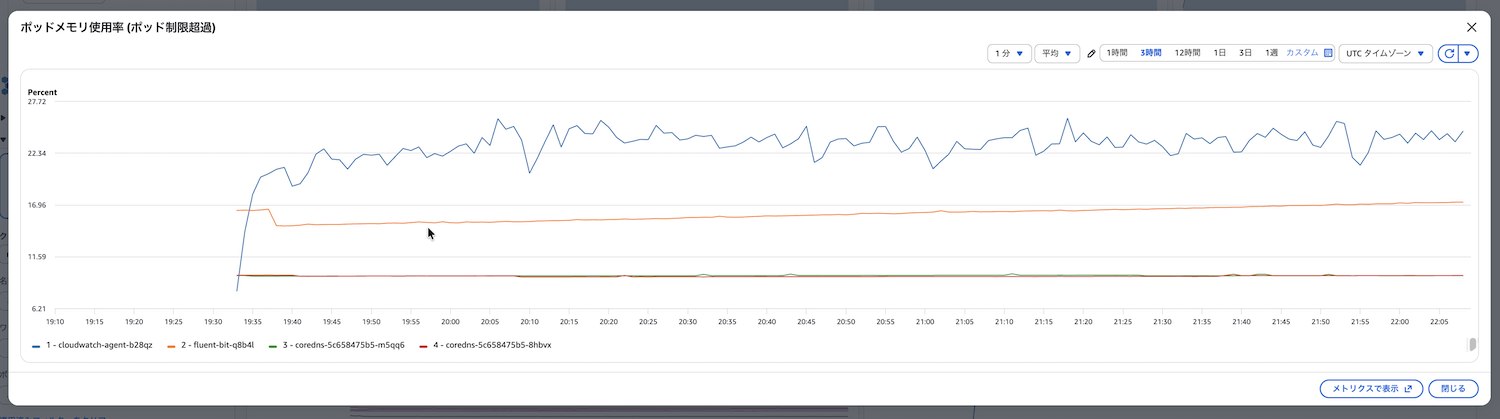
確認すべきポイント
以下の点を定期的に確認します。
- Podのメモリ使用率がPodの制限(limit)の80%を超えていないか
- メモリ使用率が時間とともに増加していないか(メモリリークの可能性)
- どのPodがメモリ制限に近づいているか
問題が見つかった場合の対応
特定のPodのメモリ使用率が高い場合、以下の手順で調査と対応を行います。まず、Container InsightsのPodビューでメモリ使用率が高いPodを特定します。次に、そのPodの時系列グラフでメモリ使用率の推移を確認します。
# Podの詳細情報とリソース制限を確認
$ kubectl describe pod <pod-name> -n
# Podのメモリ使用状況をリアルタイムで確認
$ kubectl top pod <pod-name> -n <namespace> メモリ使用率が徐々に増加している場合、メモリリークの可能性を疑います。対応策としては以下が考えられます。
- Podのメモリ制限(limits)を増やす
- アプリケーションにメモリリークがないか調査し修正する
- 一時的な対応としてPodを再起動してメモリを解放する
- Podの水平スケーリングを検討し、負荷を分散させる
ポッドCPU使用率(ポッド制限超過)(pod_cpu_utilization_over_pod_limit)
PodのCPU使用率がPodに設定されたCPU制限(limit)に対してどの程度の割合かを示します。PodがCPU制限に達するとCPUスロットリング(CPU Throttling)が発生します。メモリ制限と異なりPodは強制終了されませんが、以下の問題が発生します。
- CPUの使用が制限され、アプリケーションの処理速度が大幅に低下する
- APIのレスポンスタイムが遅くなる
- バッチ処理やデータ処理の完了時間が長くなる
- ユーザー体験が悪化する
このメトリクスを監視することで、CPUスロットリングが発生する前にCPU制限の見直しやアプリケーションの最適化、水平スケーリング(Pod数の増加)を検討できます。
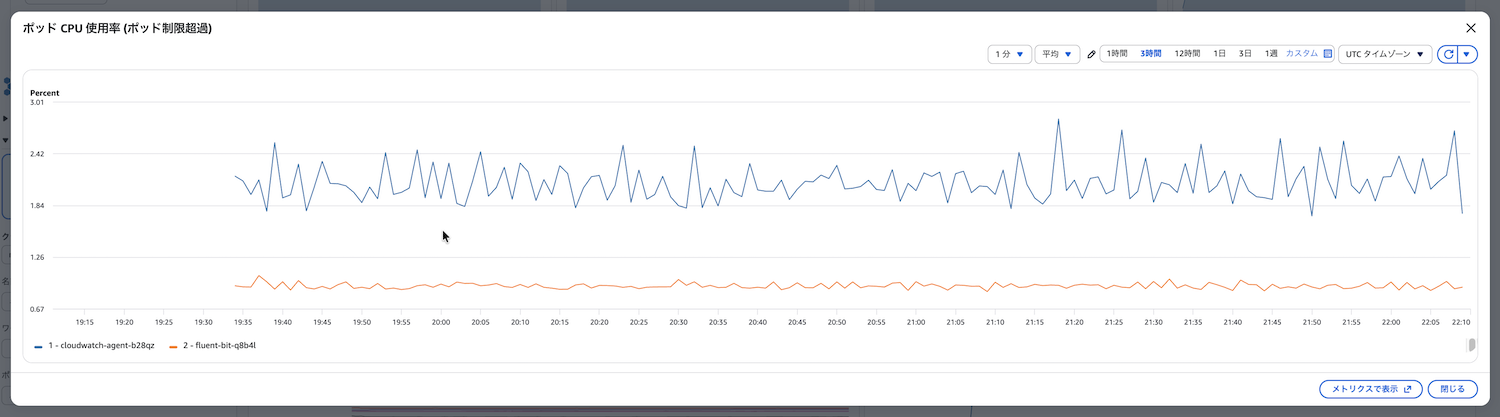
確認すべきポイント
以下の点を定期的に確認します。
- PodのCPU使用率がPodの制限(limit)に達していないか
- CPU使用率が100%で張り付いていないか(スロットリング発生の兆候)
- どのPodがCPU制限に達しているか
問題が見つかった場合の対応
PodのCPU使用率が高くスロットリングが発生している場合、以下の手順で調査と対応を行います。まず、Container InsightsのPodビューでCPU使用率が高いPodを特定します。次に、そのPodの時系列グラフでCPU使用率の推移を確認します。
# PodのCPU使用状況をリアルタイムで確認
$ kubectl top pod <pod-name> -n
# Podの詳細情報とリソース制限を確認
$ kubectl describe pod <pod-name> -n <namespace> 対応策としては以下が考えられます。
- PodのCPU制限(limits)を増やす
- Horizontal Pod Autoscaler(HPA)を設定し、負荷に応じてPod数を自動的に増やす
- アプリケーションのCPU使用効率を最適化する(プロファイリングツールで分析)
- リソース要求(requests)とリミット(limits)のバランスを見直す
ベストプラクティス
ここからは、Container Insightsを効果的に活用するためのベストプラクティスを紹介します。
リソース制限の適切な設定
KubernetesではPodにリソース制限を設定しない場合、Podはノード上のありったけのリソースを使おうとします。これにより、特定のPodが大量のCPUやメモリを消費し、同じノード上の他のPodがリソース不足に陥る可能性があります。
このようなリソース競合を防ぐために、Podごとにリソースリクエスト(requests)とリソースリミット(limits)を設定することが重要です。
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"適切な値を設定するには、Container Insightsで収集したメトリクスを活用します。Podビューで各Podの実際のCPU使用率とメモリ使用率を確認し、その値を基準にリソース制限を調整します。例えば、あるPodの平均メモリ使用量が200MiB程度であれば、requestsを256MiB、limitsを512MiB(余裕を持たせるため)に設定するといった具合です。
定期的にContainer Insightsでメトリクスをレビューし実際の使用状況に合わせてリソース制限を見直すことで、リソースの無駄を減らしつつ安定した運用を実現できます。
定期的なメトリクスレビュー
アプリケーションの開発を続けていくと、いつの間にかPodのメモリ使用量が増えていたり、特定のPodだけリソース消費が多くなったりすることがあります。デプロイ直後にメトリクスを確認するのとは別に、週次または月次でContainer Insightsのダッシュボードを確認し、負荷の傾向が変わっていないかをレビューしましょう。
確認すべき主なポイントは以下の通りです。
- メモリ使用率が徐々に増加していないか(メモリリークの兆候)
- 特定のPodだけリソース消費が多くないか(負荷の偏り)
- ノード間で負荷が不均等になっていないか(スケジューリングの問題)
これらのトレンドを早期に発見することで、リソース不足によるPodの強制終了やパフォーマンス劣化といった障害を未然に防ぐことができます。問題を発見したら、リソース制限の見直しやアプリケーションの最適化、Podの配置戦略の調整などを検討します。
アラームとの組み合わせ
第20回で設定したCloudWatchアラームは、ノード全体のメモリ使用率やCPU使用率が高くなったことを通知してくれます。しかし、アラームだけでは「どのPodが原因なのか」までは分かりません。
そこで、アラームとContainer Insightsを組み合わせることで、効率的なトラブルシューティングが可能になります。
具体的なワークフロー- CloudWatchアラームが発報(例:ノードメモリ使用率が80%を超えた)
- Container InsightsのPodビューを開き、メモリ使用率順にソートして原因Podを特定
- 特定したPodの詳細を確認し、リソース制限の見直しや対応を実施
この組み合わせにより、問題の通知から原因特定までの時間を大幅に短縮できます。アラームは「問題が起きたこと」を素早く通知し、Container Insightsは「どこに問題があるのか」を詳しく教えてくれる、という役割分担です。
ログとメトリクスの相関分析
Container Insightsのメトリクスは「何が起きているか」を数値で示してくれます。しかし「なぜそれが起きているのか」という根本原因までは分かりません。そこで、メトリクスとCloudWatch Logsを組み合わせることで問題の全体像を把握できます。
メトリクスとログの役割分担- メトリクス: 問題の発見(例:Podのメモリ使用率が90%に達している)
- ログ: 原因の特定(例:アプリケーションでメモリリークが発生している)
- Container Insightsで異常なメトリクスを発見(例:特定のPodで再起動が頻発)
- CloudWatch LogsでそのPodのログを確認し、エラーメッセージを探す
- ログから根本原因を特定(例:
OutOfMemoryErrorが記録されている) - 原因に応じた対応を実施(例:メモリ制限を増やす、メモリリークを修正)
メトリクスだけを見ていても「再起動が多い」という事実しか分かりませんが、ログと組み合わせることで「なぜ再起動しているのか」が明らかになり、適切な対応ができるようになります。
コスト管理
監視は重要ですが、コストとのバランスも考慮する必要があります。前回で学んだように、Container Insightsは収集される監視データ(Observations)とログのストレージに料金がかかります。クラスターの規模(ノード数、Pod数、サービス数など)が大きくなるほど収集されるObservationsの数が増加し、料金も比例して増加します。
コストを抑えつつ、必要な監視を維持するための工夫をいくつか紹介します。
環境ごとに有効化を使い分ける
開発環境ではContainer Insightsを無効化してコストを削減し、本番環境でのみ有効化するという運用も検討できます。開発環境では基本的なメトリクスのみで十分な場合が多く、詳細な監視は本番環境に集中させることでコストを最適化できます。
ログの保存期間を調整する
CloudWatch Logsの保存期間を短く設定することで、ログストレージのコストを抑えることも可能です。例えば、デバッグ目的のログは7日間、重要なログは30日間といった具合に、ログの種類に応じて保存期間を調整します。
監視の価値とコストのバランスを定期的に見直し、必要な監視を維持しながら無駄なコストを削減していくことが重要です。
おわりに
今回(第22回)では、Container Insightsダッシュボードの活用方法と監視のベストプラクティスについて学びました。
Container Insightsダッシュボードを使ってクラスター全体のリソース使用状況を可視化し、特定のPodやノードの問題を迅速に特定できるようになりました。パフォーマンスダッシュボードとマップビューの2つの表示方法を使い分けることで目的に応じた監視が可能です。
監視すべき重要なメトリクスとしてノードメモリ使用率、ノードディスク使用率、Podのコンテナ再起動回数、ポッドメモリ使用率(ポッド制限超過)、ポッドCPU使用率(ポッド制限超過)を紹介しました。各メトリクスでは確認すべきポイントだけでなく、問題が見つかった場合の具体的な調査手順と対応策も合わせて説明しました。これにより、メトリクスの異常を発見してから対応までの流れを一貫して理解できるようになりました。
前回と今回の2回にわたって学んだContainer Insightsにより、以下が実現できます。
- Kubernetesレベルの詳細監視: Pod、コンテナ、ノードレベルのメトリクスを収集・可視化
- 問題の迅速な特定: どのPodやノードに問題があるかを素早く特定
- リソース最適化: メトリクスを基に、リソースリクエストとリミットを適切に調整
- トラブルシューティングの効率化: メトリクスとログを組み合わせて、根本原因を特定
監視は一度設定して終わりではなく、継続的な改善が重要です。Container Insightsのダッシュボードを定期的に確認し、メトリクスのトレンドを分析することで問題を未然に防ぎ、安定したKubernetes運用を実現できます。
次回(第23回)は、AWS Cost Explorerを使ったインフラコスト管理について解説します。Terraformで構築したAWSリソースのコストを可視化し、環境ごとのコスト内訳を分析して予算アラートを設定する方法を学びます。
この記事をシェアしてください
関連記事
「AWS Cost Explorer」と「AWS Budgets」でインフラのコストを管理しよう
4月21日 6:30
Kubernetesアプリケーションのモニタリングことはじめ
2021年10月22日 6:30
Oracle Cloud Hangout Cafe Season4 #4「Observability 再入門」(2021年9月8日開催)
2024年4月23日 6:30
Kubernetesの信頼性を高める! カオスエンジニアリングツール「Krkn」
2025年10月15日 6:30
AWSの監視サービス「CloudWatch」でサーバー監視を試してみよう
2024年8月9日 6:30
Kubernetesの基礎
2018年3月14日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
「Terraform」のコードを自分で書けるようになろう
2024年5月7日 6:30
WSLとWindowsの設定ファイルを「chezmoi」を使って安全に管理しよう
2025年2月19日 6:30
バージョン管理を柔軟に! プロジェクト単位で「asdf」を使いこなす
2025年5月7日 6:30
インフラエンジニアの視点で見る、DevOpsを実現するためのツールとは
2023年5月16日 6:30
CI/CDを実現するツール「GitHub Actions」を使ってみよう
2024年6月27日 10:13
WSLで「direnv」を活用してプロジェクト単位で環境変数を管理しよう
2025年5月27日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
