「CloudWatchアラーム」でシステムの問題を自動検知しよう
第20回の今回は、システムの問題を自動検知する「CloudWatch」アラームの設定方法と「Amazon SNS」による通知の設定方法を解説します。
2月17日 6:30
はじめに
第19回では「AWS CloudWatch」を使ったEKSクラスターのメトリクス監視とダッシュボードの作成方法を学びました。メトリクスを収集し、ダッシュボードで可視化することで、インフラの健全性を一目で確認できるようになりました。
しかし、ダッシュボードを定期的に確認するだけでは、問題の検知が遅れる可能性があります。24時間365日ダッシュボードを監視し続けることは現実的ではありません。この課題を解決するのが、メトリクスを自動的に監視し、異常を検知して通知する「CloudWatchアラーム」です。
なぜアラームが必要なのか
例えば、深夜にCPU使用率が急増した場合、翌朝出勤するまで気付かない可能性があります。その間にアプリケーションのレスポンスが遅くなり、ユーザーに影響を与えてしまうかもしれません。
CloudWatchアラームを設定することで、このような問題を早期に検知し、迅速に対応できます。本記事では、CloudWatchアラームの設定方法と「Amazon SNS」を活用した通知の設定方法を解説します。
なお、メモリ使用率やディスク使用率のアラームを設定するには「Container Insights」の有効化が必要です。Container Insightsについては次回(第21回)で詳しく解説しますが、本記事で設定方法を紹介します。
CloudWatchアラームとは
CloudWatchアラームはメトリクスを監視し、設定したしきい値を超えたときにアクションを実行する機能です。
例えば、CPU使用率が80%を超えたら通知を受け取ることでパフォーマンス問題を早期に検知し、ノード数を増やすなどの対策を実施できます。
アラームの状態
CloudWatchアラームには3つの状態があります。
- OK: しきい値を下回っている(正常)
- ALARM: しきい値を超えている(異常)
- INSUFFICIENT_DATA: データが不足している(初期状態や監視対象が停止中)
アラームの状態は、CloudWatchコンソールの「アラーム」画面で確認できます。状態が変化したときに、メール送信やLambda関数の実行などのアクションを設定できます。
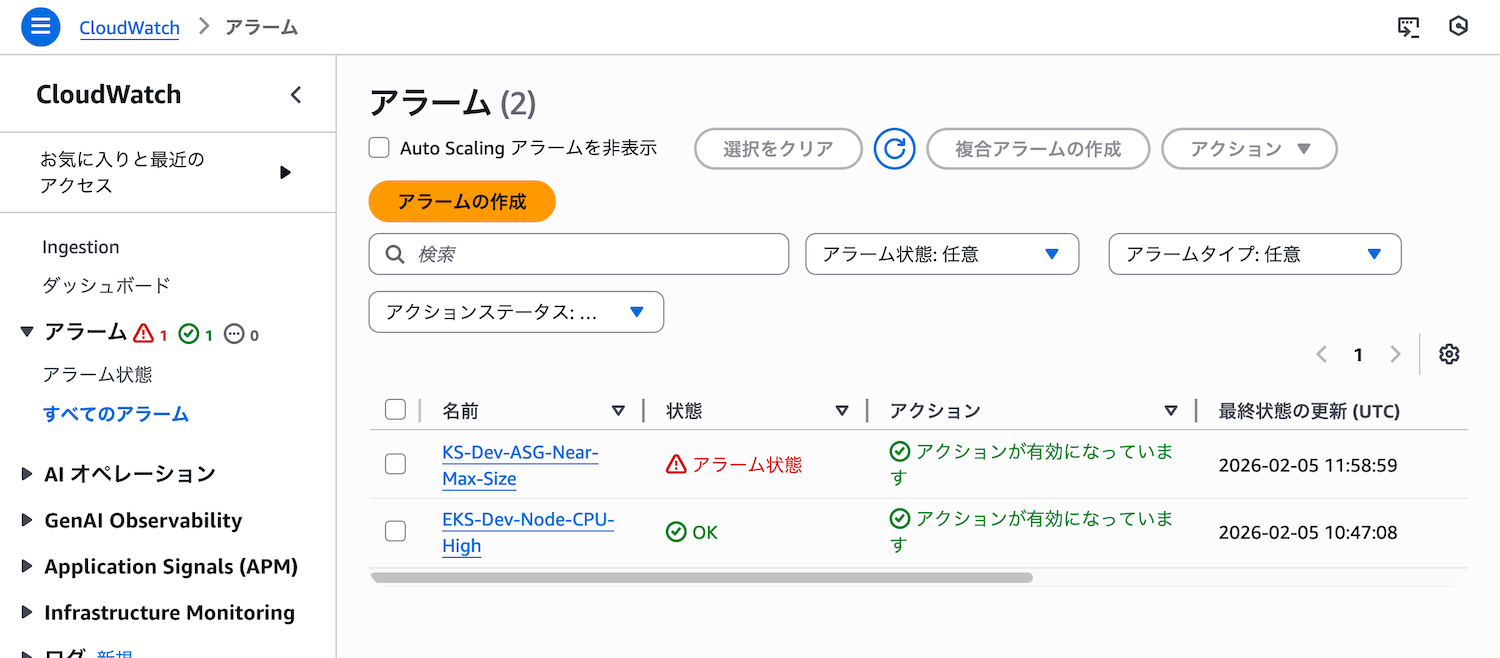
アラームの作成手順
CloudWatchコンソールの左側メニューから「アラーム」→「すべてのアラーム」を選択し、「アラームの作成」をクリックします。
ステップ1: メトリクスの選択
「メトリクスの選択」をクリックし、「EC2」→「Auto Scaling グループ別」を選択します。第19回で説明したように、Auto Scalingグループ別にすることでノードの増減に自動で追従できます。
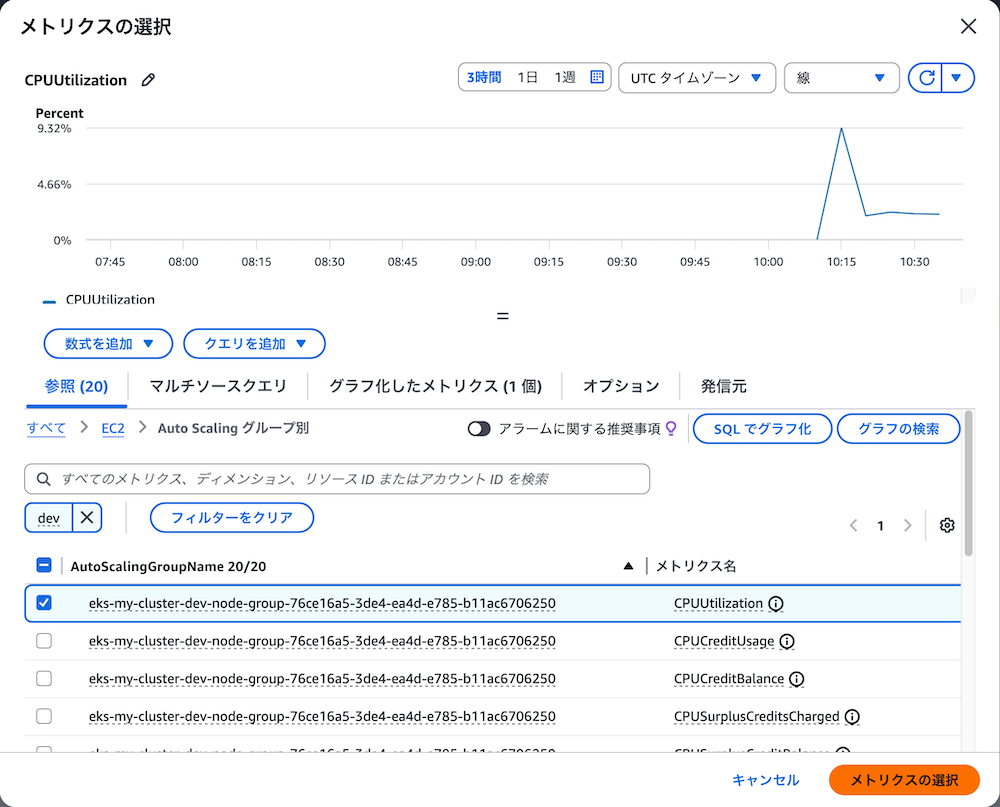
開発環境のAuto Scaling Groupを選択し(検索窓で「dev」と入力すると見つけやすい)、「CPUUtilization」→「メトリクスの選択」をクリックします。
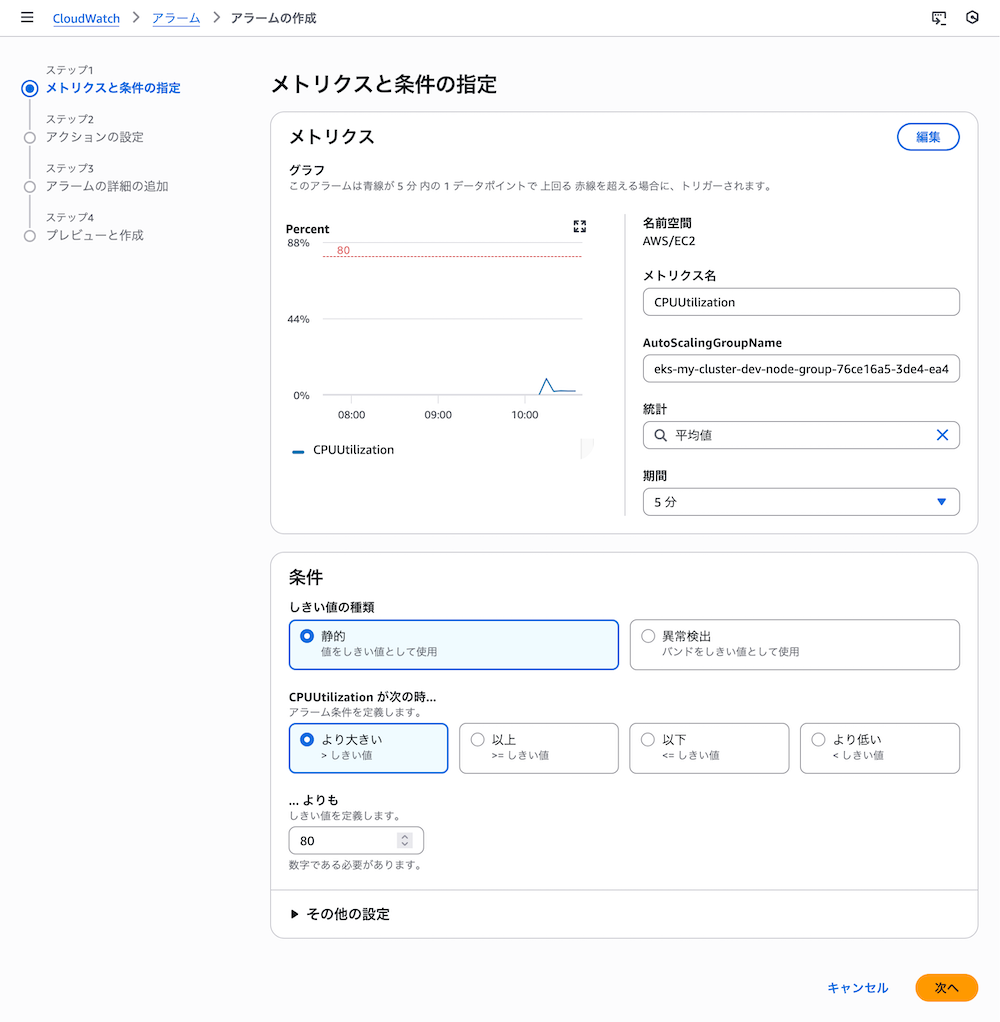
ステップ2: 条件の設定
しきい値を設定します。
- 統計: Average(平均)
- 期間: 5分
- しきい値のタイプ: 静的
- アラーム条件: 次の時より大きい(Greater)
- しきい値: 80
これで、5分間の平均CPU使用率が80%を超えたときにアラームが発報されます。
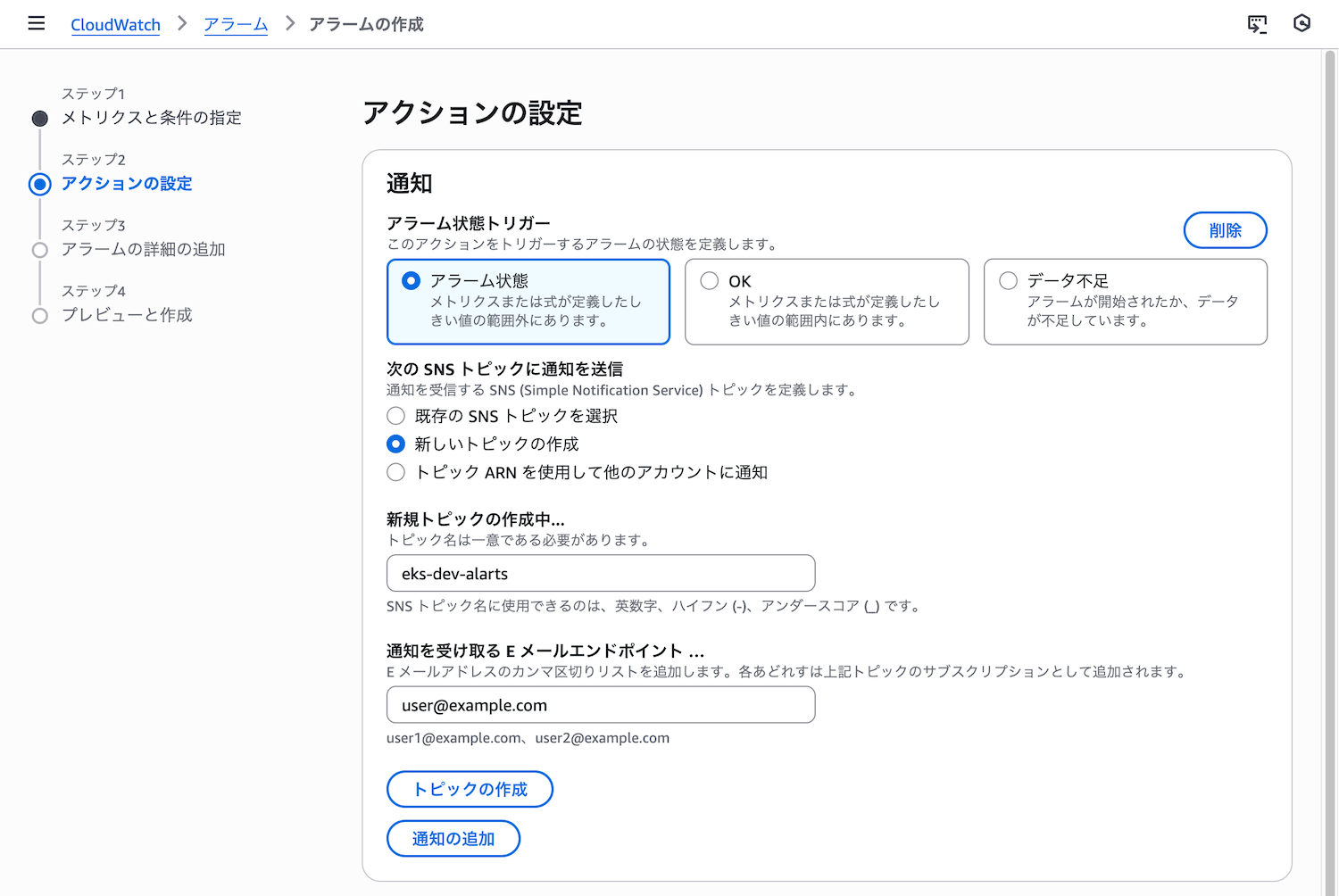
ステップ3: アクションの設定
アラームが発報されたときのアクションを設定します。
- アラーム状態のトリガー: アラーム状態
- SNSトピックの選択: 新しいトピックの作成
- トピック名:
eks-dev-alerts - 通知を受信するメールエンドポイント: 自分のメールアドレス
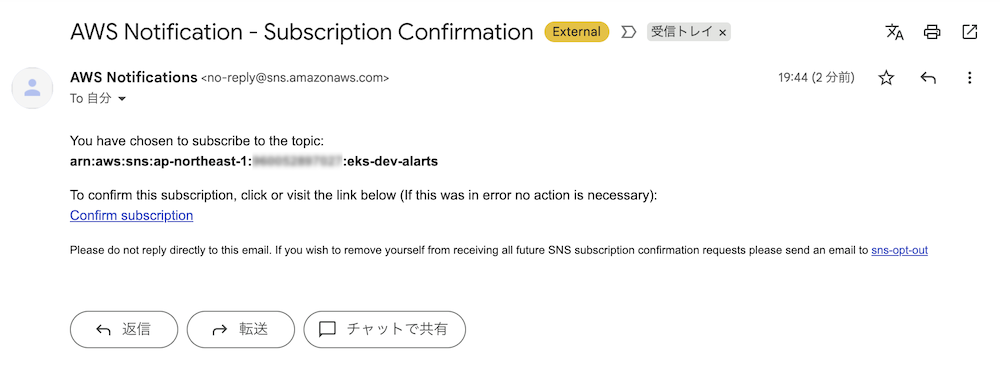
「トピックの作成」をクリックすると指定したメールアドレスに確認メールが送信されます。メール内のリンクをクリックして、サブスクリプションを確認します。
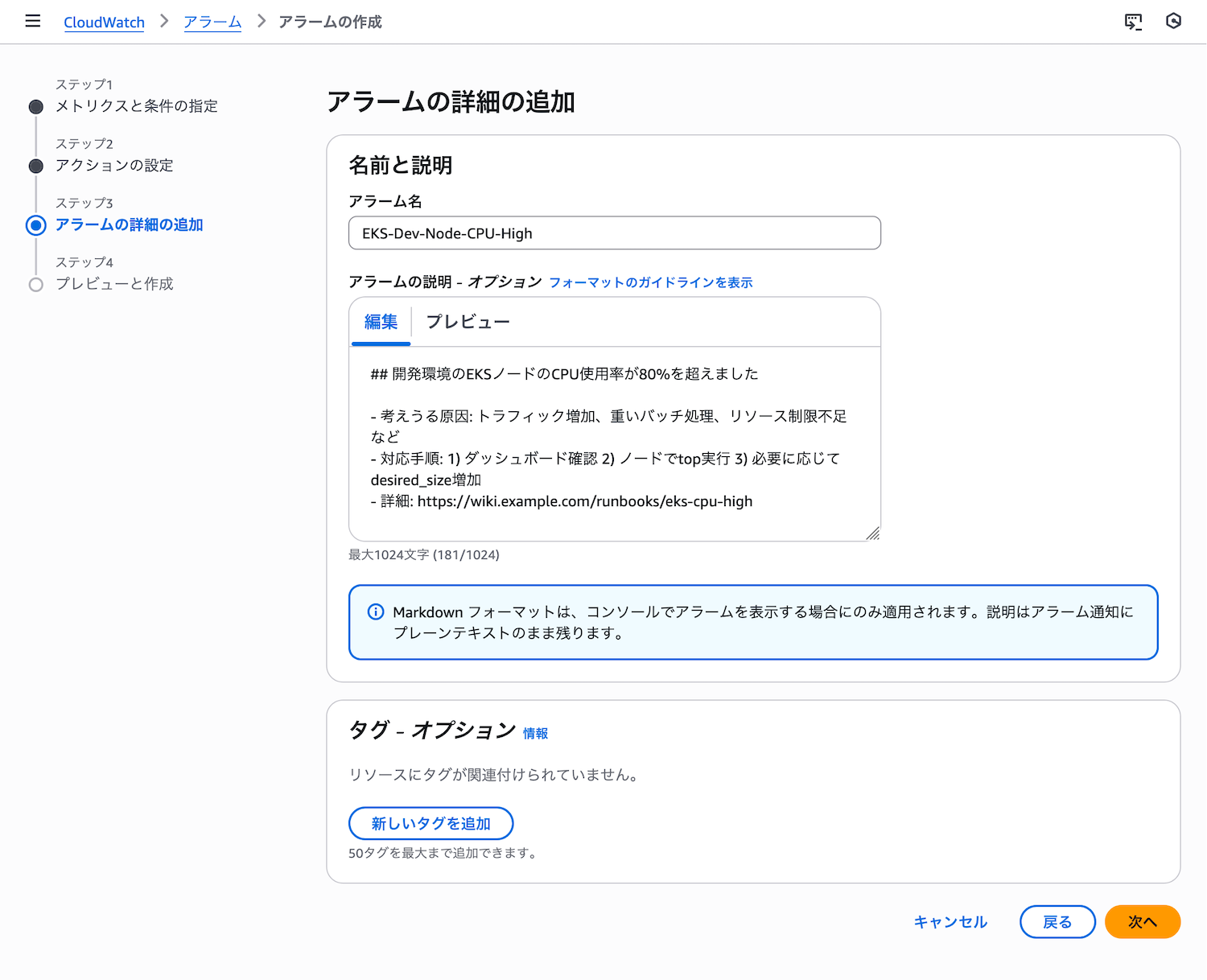
ステップ4: アラーム名と説明の設定
- アラーム名:
EKS-Dev-Node-CPU-High - アラームの説明:
開発環境のEKSノードのCPU使用率が80%を超えました
ステップ5: アラームの確認と作成
設定内容を確認して「アラームの作成」をクリックします。
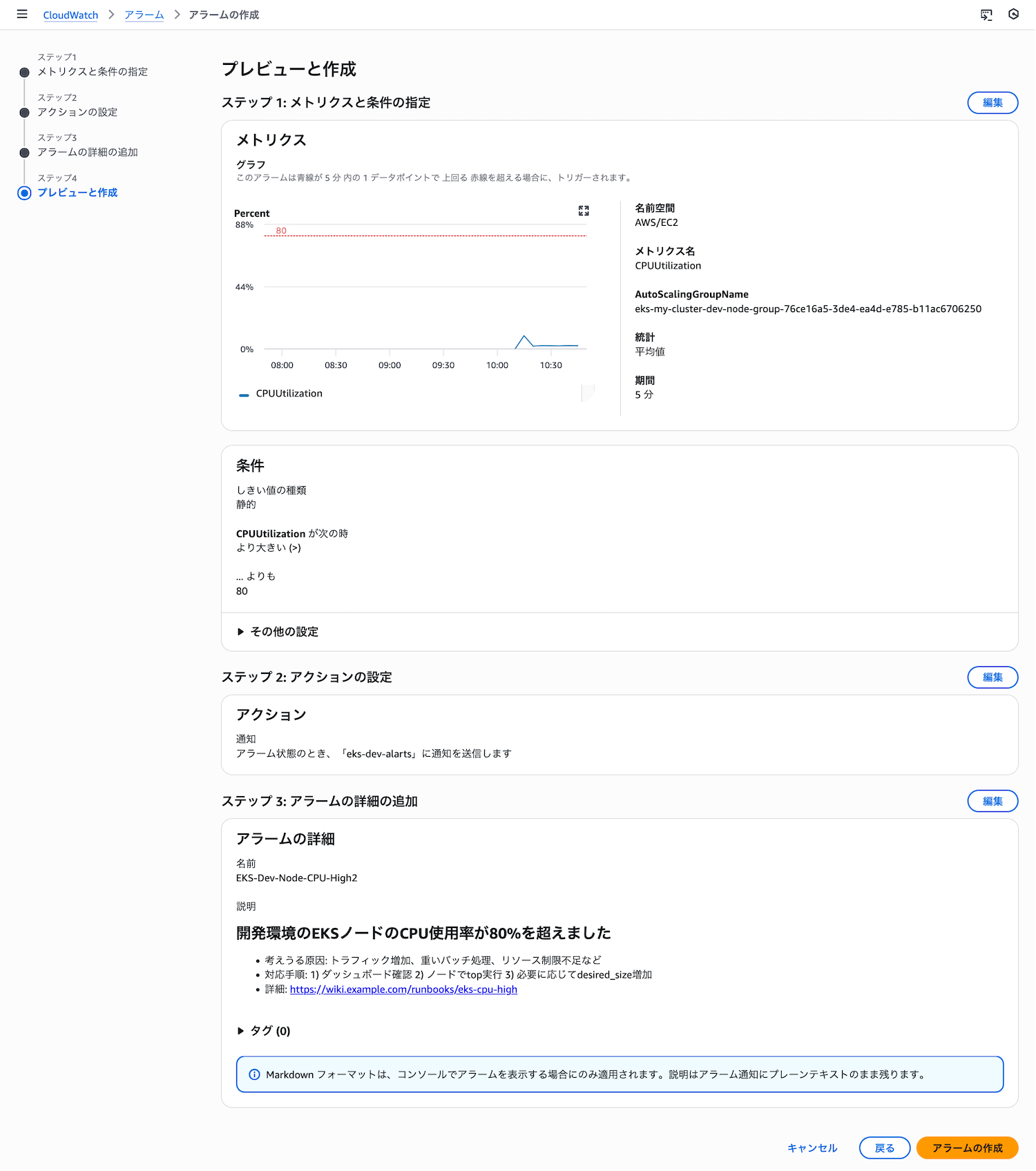
アラームが作成されると、一覧に表示されます。
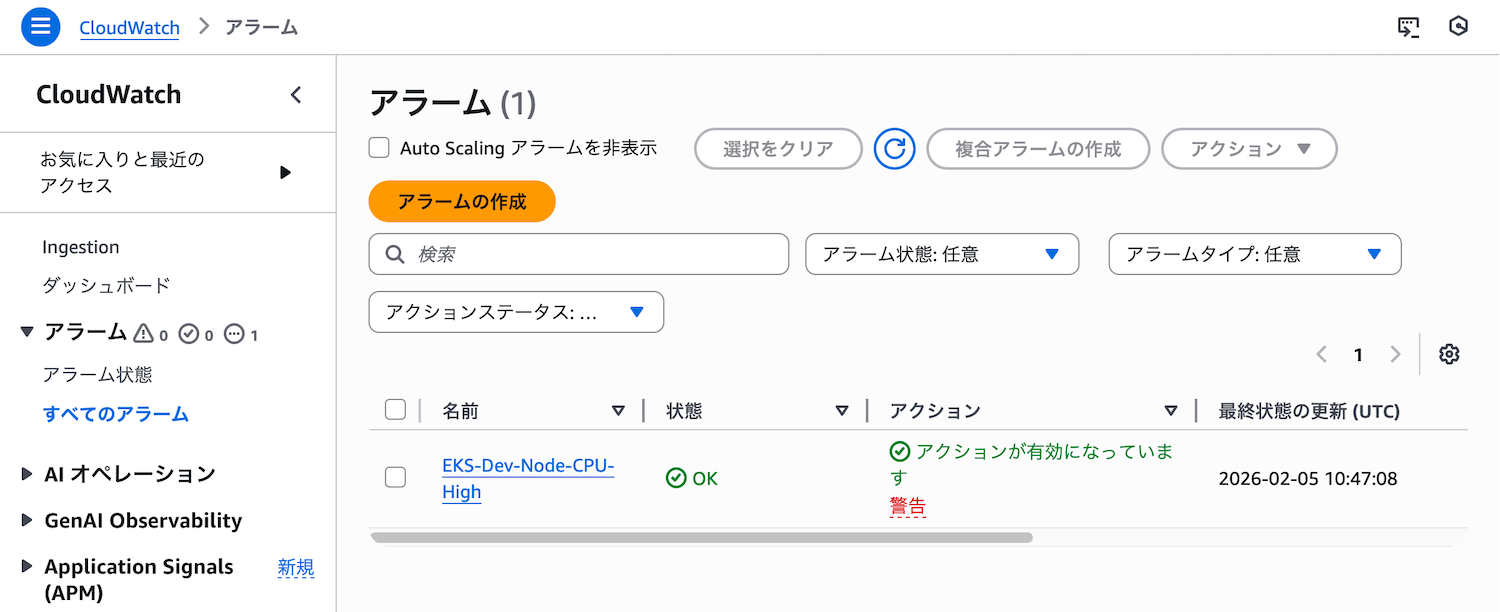
Auto ScalingとCloudWatchアラームの違い
ここで、重要な疑問が浮かぶかもしれません。「EKSのAuto Scaling GroupはCPU使用率に応じてノード数を自動的に増減するのに、なぜCloudWatchアラームでCPU使用率を監視する必要があるのか?」という疑問です。
Auto Scalingの役割は設定されたポリシーに基づいて自動的にリソースを調整することです。例えば、CPU使用率が70%を超えたら、ノードを自動的に追加します。
一方、CloudWatchアラームの役割は異常を検知して人間に通知することです。以下のような状況を検知します。
- Auto Scaling Groupが最大サイズに達している: これ以上ノードを増やせない状態
- Auto Scalingが対応していないメトリクスの異常: メモリ使用率、ディスク使用率など
- 想定外のリソース消費: Auto Scalingが動作する前に、問題の根本原因を調査する必要がある場合
つまり、Auto Scalingは「自動対応」、CloudWatchアラームは「検知と通知」という異なる役割を持っています。両方を組み合わせることで、自動復旧と人間による問題対応の両立が可能になります。
複数のアラームを設定
CPU使用率以外にも、以下のアラームを設定することをお勧めします。
EKSクラスターで監視すべきメトリクスの全体像については、第19回の「AWS公式の推奨監視項目」を参照してください。ここでは、基本的なアラームの設定例を紹介します。
Auto Scaling Groupの最大サイズ検知アラーム
Auto Scaling Groupが最大サイズに達すると、それ以上ノードを増やせなくなります。この状態を検知するために「Metric Math」を使ったアラームを設定します。
Metric Mathを使うと複数のメトリクスを組み合わせて計算できます。今回はGroupInServiceInstances(稼働中のインスタンス数)とGroupMaxSize(最大サイズ)を比較します。
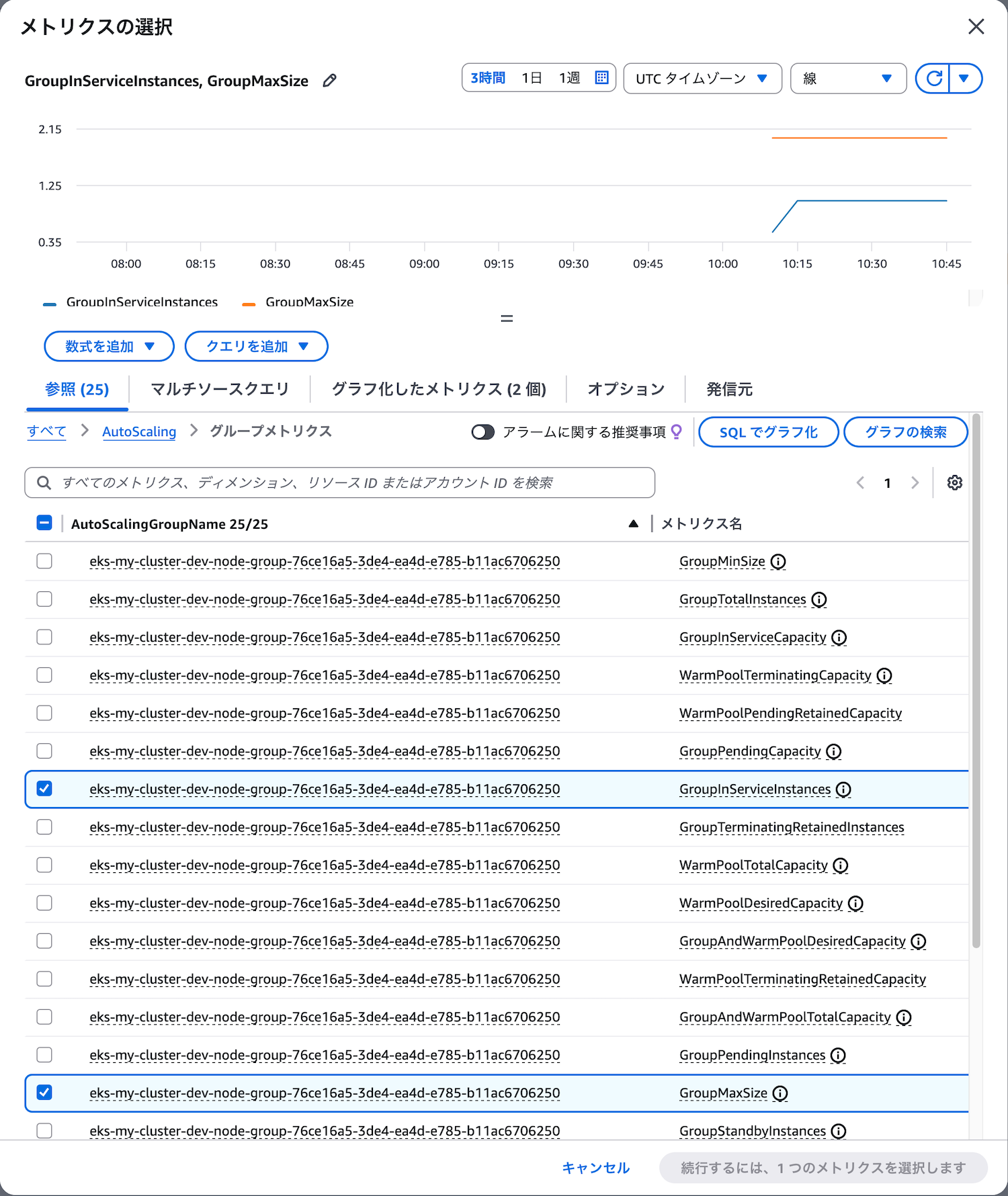
アラーム作成時に「メトリクスの選択」で「Auto Scaling」→「グループメトリクス」を選択し、以下の2つのメトリクスを追加します。それぞれのメトリクスの統計は「Maximum(最大)」を選択してください。瞬間的にでも最大サイズに達した場合、即座に対応が必要なため、最大値を監視します。
- メトリクス1(m1):
GroupInServiceInstances(統計: Maximum) - メトリクス2(m2):
GroupMaxSize(統計: Maximum)
次に「グラフ化されたメトリクス」タブで「数式を追加」をクリックし、「空の式」を選択します。数式の入力欄に以下の式を入力します。
(m1/m2)*100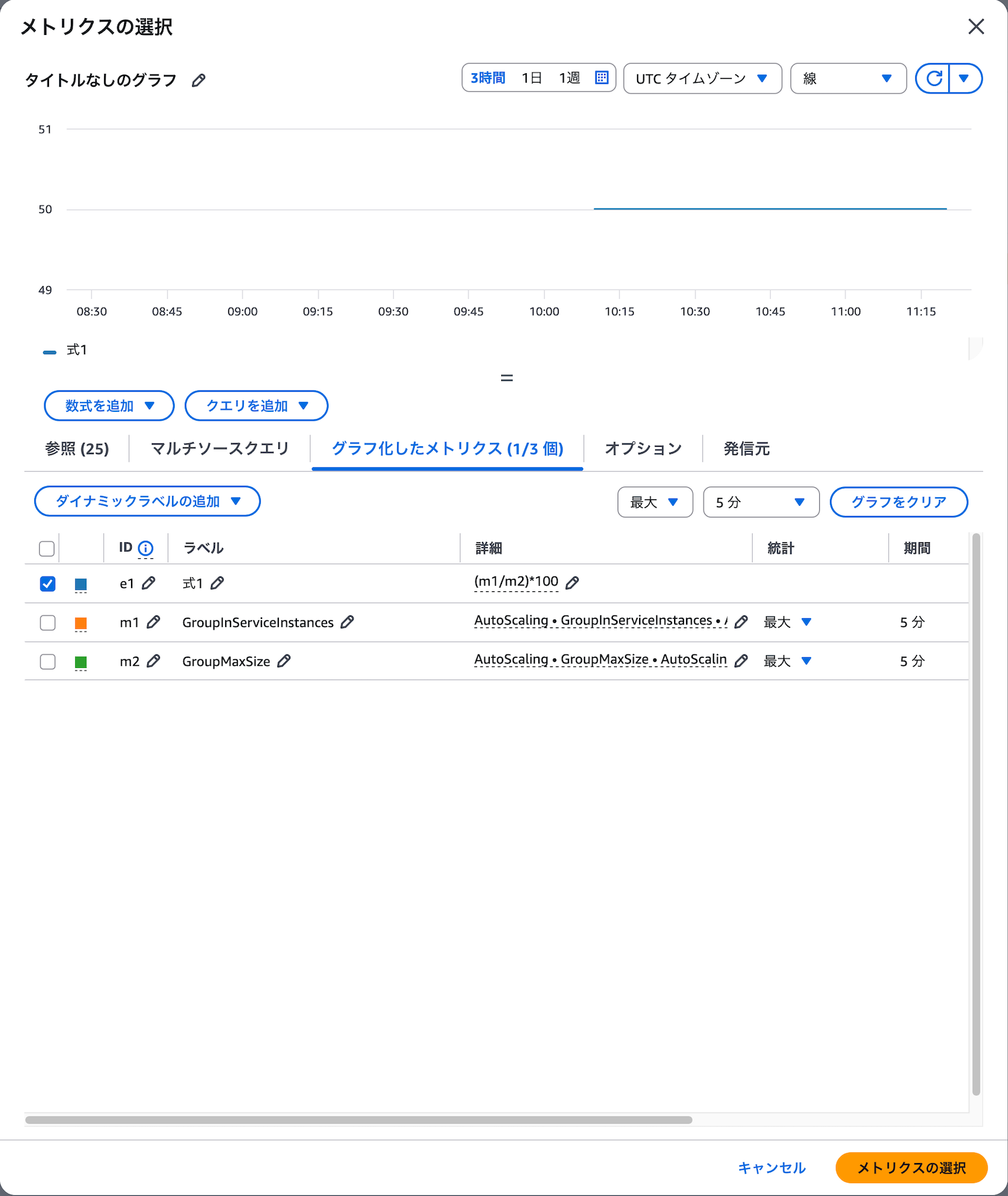
この式は、現在の稼働インスタンス数が最大サイズの何%かを計算します。条件設定でしきい値を95に設定します。これで、稼働インスタンス数が最大サイズの95%に達したときにアラームが発報されます。
- 統計: Maximum(最大)
- 期間: 5分
- しきい値: 95(%)
- アラーム名:
EKS-Dev-ASG-Near-Max-Size - アラームの説明:
開発環境のAuto Scaling Groupが最大サイズに近づいています
このアラームが発報されたら、以下の対応を検討します。
- Terraformのコードで
max_sizeを増やす - アプリケーションのリソース消費を最適化する
- 不要なPodやワークロードを削除する
監視を推奨するその他のアラーム
基本的なCPU監視とASG最大サイズ検知に加えて、以下のアラームも設定することをお勧めします。
ネットワークトラフィックアラーム
ネットワーク送信量が異常に多い場合、DDoS攻撃や設定ミスによるデータ転送などが発生している可能性があります。
- メトリクス:
NetworkOut - しきい値: 1GB(1,073,741,824バイト)
- 統計: Sum(合計)
- 期間: 5分
- アラーム名:
EKS-Dev-Node-Network-High - アラームの説明:
開発環境のEKSノードのネットワーク送信量が5分間で1GBを超えました
メモリ使用率アラーム(Container Insights使用時)
メモリ不足は、OOMKillerによるPodの強制終了やノードの不安定化を引き起こします。
- メトリクス:
node_memory_utilization - しきい値: 80%
- 統計: Average(平均)
- 期間: 5分
- アラーム名:
EKS-Dev-Node-Memory-High
本番環境ではメモリ監視の導入を強く推奨します。
ディスク使用率アラーム(Container Insights使用時)
ディスク容量不足はPodの起動失敗やノードの異常につながるため、本番環境では監視を強く推奨します。
- メトリクス:
node_filesystem_utilization - しきい値: 80%
- 統計: Average(平均)
- 期間: 5分
- アラーム名:
EKS-Dev-Node-Disk-High
※メモリ使用率とディスク使用率の監視には、Container Insightsの有効化が必要です。Container Insightsについては次回(第21回)で詳しく解説します。
Amazon SNSによる通知の設定
Amazon SNSとは
Amazon SNS(Simple Notification Service)はメッセージ配信サービスです。CloudWatchアラームと連携することで、メール、SMS、Slackなど、さまざまな通知先にアラートを送信できます。
前述のアラーム作成手順でSNSトピックを作成し、メール通知を設定しました。ここではSNSの仕組みと、複数の通知先を設定する方法を解説します。
SNSトピックとサブスクリプション
SNSでは「トピック」と「サブスクリプション」という概念を使います。
- トピック: 通知のグループ(例:
eks-dev-alerts) - サブスクリプション: 通知先の設定(例: メールアドレス、SMSエンドポイント、Lambda関数)
1つのトピックに複数のサブスクリプションを設定することで、1つのアラームから複数の通知先にメッセージを送信できます。
メール通知の追加
追加のメールアドレスに通知を送るには、SNSコンソールでサブスクリプションを追加します。SNSコンソールの左側メニューから「トピック」を選択し、eks-dev-alertsトピックをクリックします。
「サブスクリプションの作成」をクリックし、プロトコルで「メール」を選択します。エンドポイントにメールアドレスを入力して「サブスクリプションの作成」をクリックします。
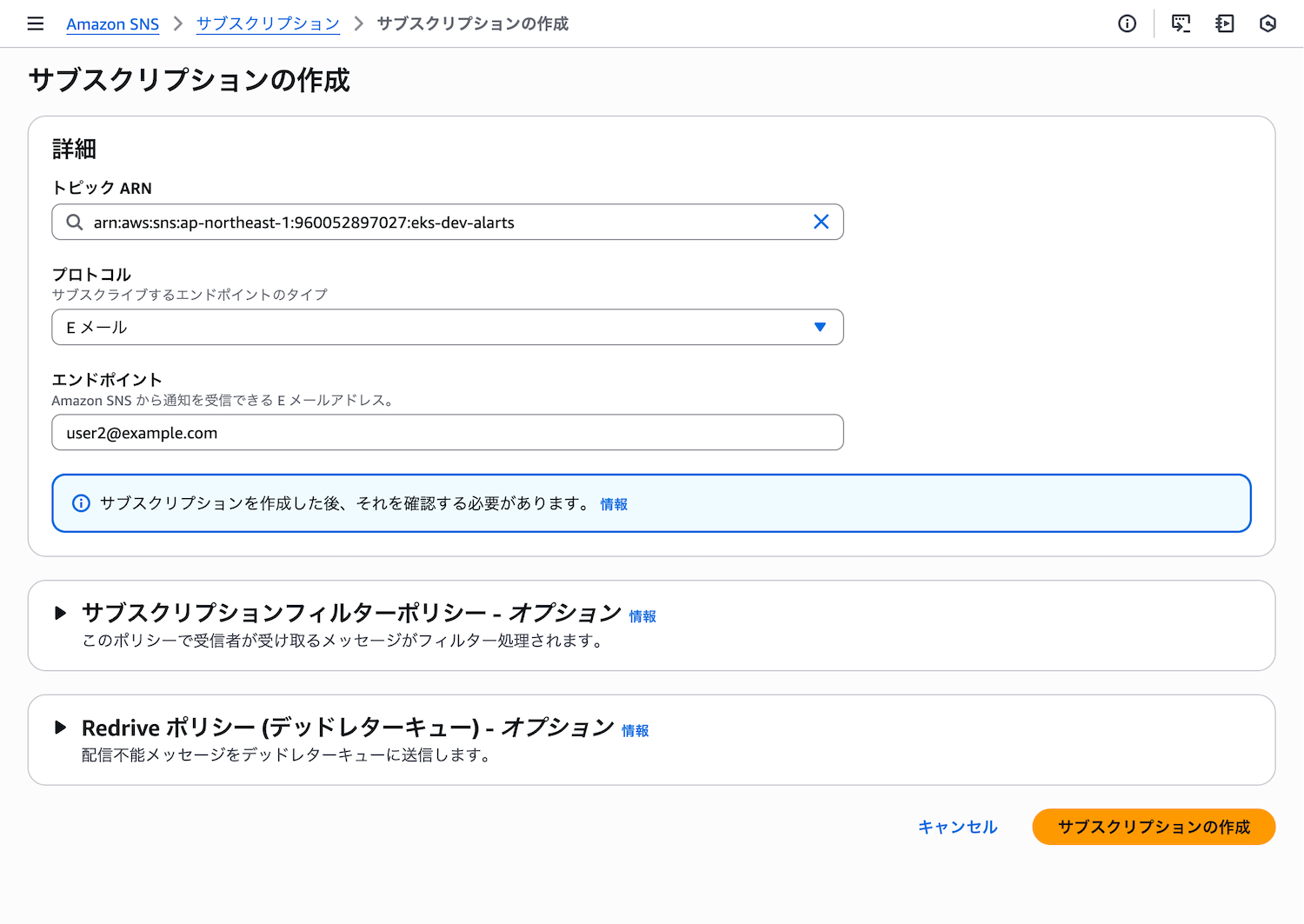
追加したメールアドレスに確認メールが送信されるので、リンクをクリックして確認します。
Slack通知の設定
Slackに通知を送るには「Amazon Q Developer」(AWS Chatbotの後継サービス)または「Lambda関数」を使用します。
Amazon Q Developerを使う方法
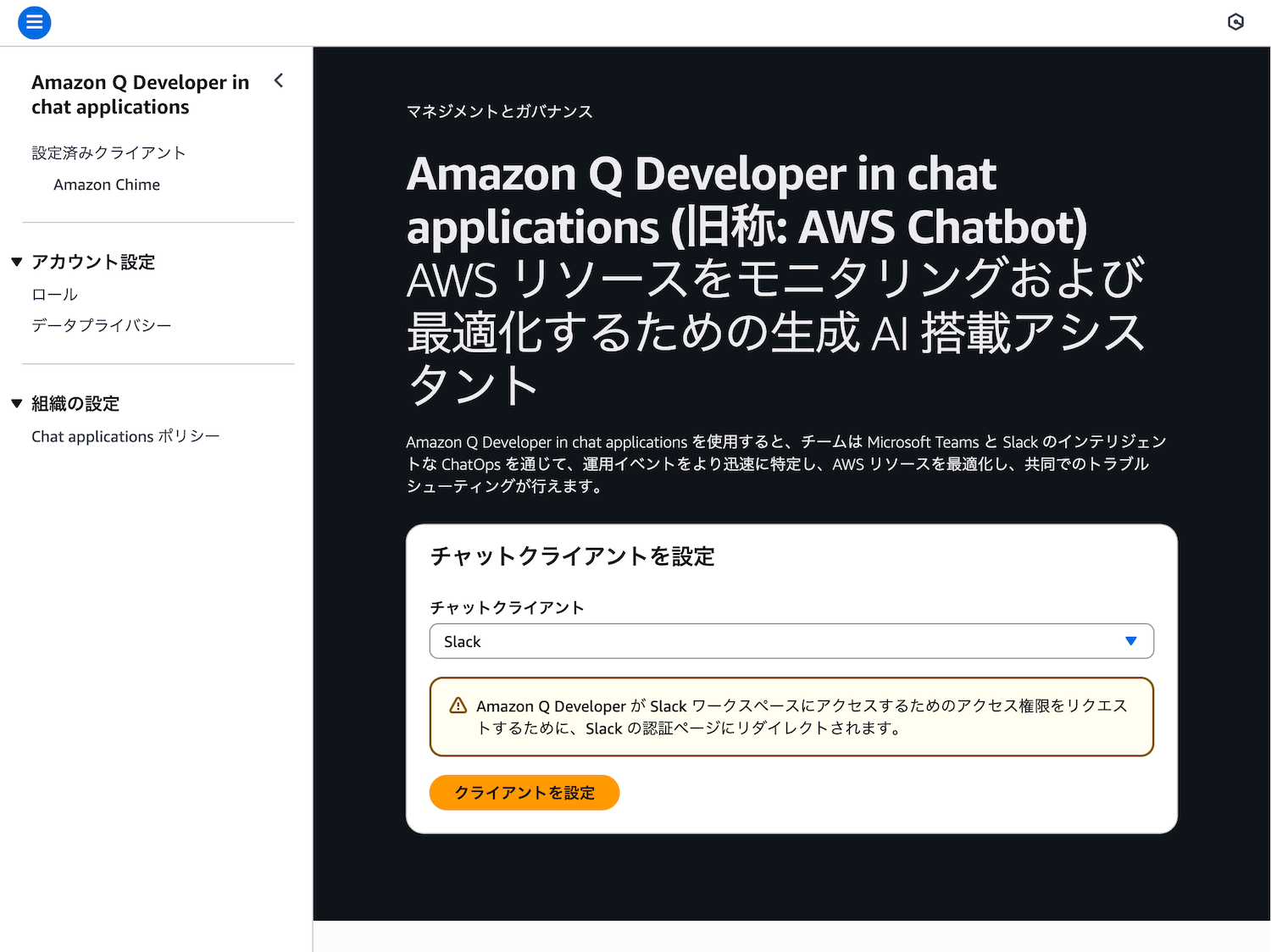
Amazon Q Developerは、SNSとSlackを簡単に連携できるサービスです。
- Amazon Q Developerコンソールを開く
- 「新しいクライアントの設定」→「Slack」を選択
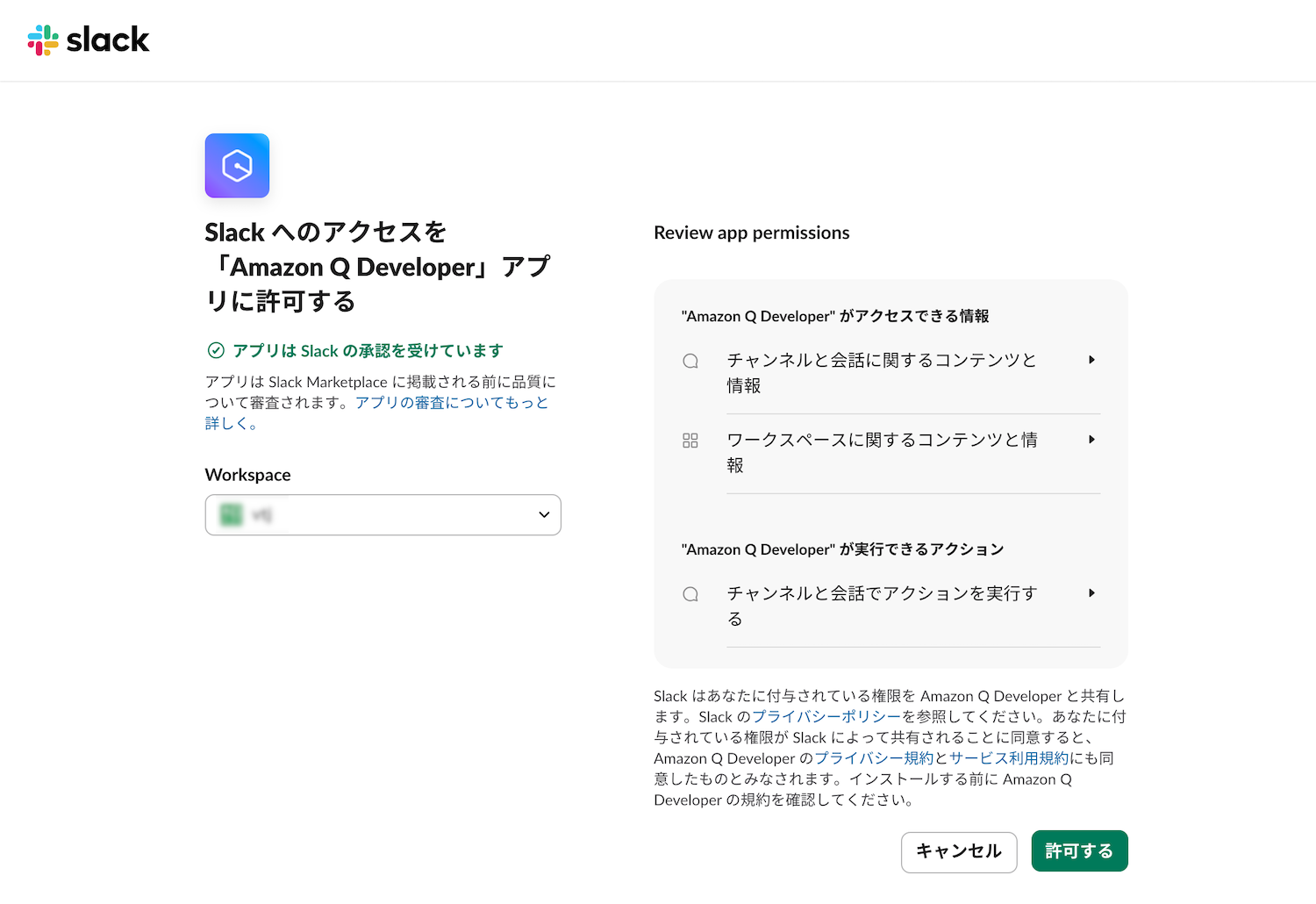
- Slackワークスペースにサインインして、アプリを承認
- チャンネルを選択(例:
#eks-alerts) - SNSトピックで
eks-dev-alertsを選択 - 設定を保存
これで設定完了です。CloudWatchアラームが発報されるとSlackチャンネルに通知が送信されます。通知にはアラーム名、状態、メトリクス情報などが含まれます。
Lambda関数を使う方法
カスタマイズした通知メッセージを送りたい場合は、Lambda関数を使ってSlack Webhook APIを呼び出します。この方法はより柔軟なメッセージフォーマットが可能ですが、コーディングが必要です。
本番環境用のSNSトピック
開発環境用のSNSトピックeks-dev-alertsを作成したら、本番環境用にもeks-prod-alertsトピックを作成し、アラームと連携させます。
環境ごとにトピックを分けることで通知先を環境ごとに変更できます。例えば、本番環境のアラームはオンコール担当者に通知し、開発環境のアラームは開発チーム全体に通知するといった使い分けが可能です。
アラーム設定のベストプラクティス
適切なしきい値の設定
アラームのしきい値は、環境やアプリケーションの特性に応じて調整する必要があります。しきい値が低すぎると誤検知(False Positive)が多発し、アラート疲れ(Alert Fatigue)を引き起こします。逆に、しきい値が高すぎると問題を見逃す可能性があります。
初期段階では、以下のように低めのしきい値から始めて、実際の運用データを基に調整することをお勧めします。ただし、適切なしきい値はアプリケーションの特性やチームの運用体制によって異なるため、プロジェクトメンバーと相談して決定してください。
初期設定(まずは問題を検知する)- CPU使用率: 60%
- メモリ使用率: 70%
- ディスク使用率: 70%
- ネットワークトラフィック: 過去1週間の平均の1.5倍
- CPU使用率: 70-80%
- メモリ使用率: 80-85%
- ディスク使用率: 80%
- ネットワークトラフィック: 過去1週間の平均の2倍
段階的なアラート
1つのメトリクスに複数のしきい値を設定することで、段階的に対応を検討できます。例えば、CPU使用率に以下のアラームを設定します。
- Warning: 60%を超えたとき(Slackに通知、監視継続)
- Critical: 80%を超えたとき(メールとSlackに通知、即座に対応)
アラームのグループ化
環境ごと、サービスごとにSNSトピックを分けることで、通知先を柔軟に設定できます。
eks-dev-alerts: 開発環境のアラートeks-prod-alerts: 本番環境のアラートrds-prod-alerts: RDSのアラート
定期的なレビュー
アラームの設定は定期的に見直す必要があります。アプリケーションの成長に伴いトラフィックパターンやリソース使用量が変化するため、しきい値を調整するようにしましょう。
週次または月次でアラームの履歴を確認し、誤検知が多いアラームはしきい値を調整し、必要なアラームが不足している場合は追加します。
アラートへの対応手順の文書化
アラームが発報されたときに、どのような対応を取るべきかを文書化しておくことが重要です。
Runbookの保管場所
簡易的な対応手順(1-3行程度)はCloudWatchアラームの説明フィールドに記載するのがおすすめです。この説明はアラート通知メールに含まれるため、アラームが発報された際に即座に確認できます。詳細なRunbookはチーム全体がアクセスできる場所(GitHub、Confluence、Notion、Wikiなど)に保存しておくのが良いでしょう。
例えば、アラーム作成時の「アラームの説明」には以下のように記載します。
開発環境のEKSノードのCPU使用率が80%を超えました。
考えうる原因: トラフィック増加、重いバッチ処理、リソース制限不足など
対応手順: 1) ダッシュボード確認 2) ノードでtop実行 3) 必要に応じてdesired_size増加
詳細: https://wiki.example.com/runbooks/eks-cpu-highCPU使用率が80%を超えた場合
- CloudWatchダッシュボードで詳細を確認
- EKSノードにSSHでログインし、
topコマンドでプロセスを確認 - 不要なプロセスがあれば終了
- CPU使用率が高い状態が続く場合はノード数を増やす
- Terraformのコードで
desired_sizeを増やす terraform applyを実行
- Terraformのコードで
このようなRunbookを用意しておくことで、担当者が不在のときでも他のメンバーが迅速に対応できます。
おわりに
本記事では、CloudWatchアラームを使った自動通知の仕組みを学びました。
CloudWatchアラームを設定することで、しきい値を超えたときに自動的に通知を受け取り、問題を早期に検知できるようになりました。Amazon SNSと連携することでメールやSlackなど、さまざまな通知先にアラートを送信できます。
これらの監視・通知の仕組みにより、以下が実現できます。
- 問題の早期検知: アラームにより、しきい値を超えたときに即座に通知
- 迅速な対応: Runbookを用意することで担当者不在時でも対応可能
- チーム全体での情報共有: Slack通知により全員がリアルタイムで状況を把握
監視は一度設定して終わりではなく、継続的な改善が重要です。アラームの履歴を定期的にレビューし、しきい値を調整し、新しいアラームを追加することで、より効果的な監視体制を構築できます。
次回は、「Container Insights」を使った詳細な監視について解説します。Container Insightsを有効化し、Kubernetesレベルのメトリクス(Pod、コンテナ、ノード)を収集・可視化する方法を学びます。
この記事をシェアしてください
関連記事
「AWS CloudWatch」でEKSクラスターを監視してみよう
1月27日 6:30
クラスターを詳細監視する「Container Insights」のセットアップと有効化【前編】
3月10日 6:30
「Amazon GuardDuty」でAWSアカウントの脅威を自動検知してみよう
6月23日 6:30
「AWS CloudTrail」でAWSアカウントの操作履歴を記録・監視してみよう
6月2日 6:30
「AWS EKS」でKubernetesクラスターを構築してコンテナアプリケーションをデプロイしてみよう
2025年10月14日 6:30
「GitHub Actions」で「Terraform」を使用してCI/CD統合を試してみよう
1月6日 6:30
バックナンバー
この記事の筆者

筆者の人気記事
「Terraform」のコードを自分で書けるようになろう
2024年5月7日 6:30
WSLとWindowsの設定ファイルを「chezmoi」を使って安全に管理しよう
2025年2月19日 6:30
バージョン管理を柔軟に! プロジェクト単位で「asdf」を使いこなす
2025年5月7日 6:30
インフラエンジニアの視点で見る、DevOpsを実現するためのツールとは
2023年5月16日 6:30
CI/CDを実現するツール「GitHub Actions」を使ってみよう
2024年6月27日 10:13
WSLで「direnv」を活用してプロジェクト単位で環境変数を管理しよう
2025年5月27日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
