「Amazon GuardDuty」でAWSアカウントの脅威を自動検知してみよう
第26回の今回は、「Amazon GuardDuty」によるAWSアカウントの脅威自動検知の仕組みと、検出結果をSlackへ通知する構成の構築手順について解説します。
6月23日 6:30
はじめに
前回では、「AWS CloudTrail」を使ってAWSアカウント上のAPI操作を記録し、CloudWatch Logsメトリクスフィルターでrootアカウントのログインを検知する仕組みを構築しました。CloudTrailは「誰が・いつ・何をしたか」を記録する基盤として機能します。
ただし、CloudTrailのログだけでは「その操作が脅威かどうか」を判断できません。例えば、深夜に普段使わないリージョンでEC2インスタンスが起動された場合、それが正常なオペレーションなのか、認証情報の漏洩による不正利用なのかは、ログ単独では判断が難しいです。
本記事では「Amazon GuardDuty」を使ってAWSアカウントの脅威を自動検知する仕組みを構築します。GuardDutyはCloudTrailのログだけでなく、VPC Flow LogsやDNSクエリログを機械学習で分析し、不審な挙動を脅威スコア付きで通知します。前回構築したCloudTrailと組み合わせることで「記録」と「検知」の両面からセキュリティ運用を強化できます。
なお、Security HubとGuardDutyを併せて解説する予定でしたが、それぞれの解説に十分な分量を取るため、本記事ではGuardDuty単独を扱い、Security Hubは次回(第27回)で解説します。
Amazon GuardDutyとは
Amazon GuardDutyは、AWSアカウントとワークロードを継続的に監視する脅威検知サービスです。AWSが管理する脅威インテリジェンスフィードと機械学習モデルを使い、悪意のある挙動や不正なアクティビティを自動検出します。
GuardDutyのデータソース
GuardDutyは、以下のデータソースを自動的に分析します。ユーザー側でログ収集設定を作る必要はありません。
- AWS CloudTrail管理イベント: API操作の履歴
- AWS CloudTrail S3データイベント: S3オブジェクトレベルの操作
- VPC Flow Logs: VPC内のネットワークトラフィック
- DNSクエリログ: VPC内のDNS問い合わせ
CloudTrailとは異なり、GuardDutyはこれらのログをユーザーのS3バケットに保存せず、GuardDuty内部で分析します。そのため、ログ保存コストを抑えつつ脅威検知を実現できます。
検出される脅威の例
GuardDutyが検出する脅威カテゴリは多岐にわたります。以下はその代表例です。
- 侵害された認証情報の利用: 普段と異なる地域からのAPI呼び出し、Torネットワーク経由のアクセス
- 暗号資産マイニング: EC2インスタンスからマイニングプール宛の通信
- 不正なリソース変更: rootアカウントによるセキュリティ設定の変更、CloudTrailの無効化
- 不審なネットワーク挙動: ポートスキャン、既知の悪意あるIPアドレスとの通信
- マルウェア感染の兆候: EC2インスタンスからC2サーバへの通信
検出結果は重要度(Low / Medium / High)付きで提示されるため、対応の優先度を判断しやすくなっています。
料金体系
GuardDutyは従量課金制です。CloudTrailイベント分析量、VPC Flow Logs / DNSクエリログの分析量に応じて課金されます。新規有効化時は30日間の無料トライアルがあり、トライアル期間中の本体機能の請求は発生しません。本記事の検証もこのトライアル期間内で完結します。
なお、S3 ProtectionやMalware Protectionなど追加機能は、本体とは別に独立したトライアル期間が設けられています。検証目的でも、AWS公式のGuardDuty料金ページで最新の課金条件を確認することを推奨します。
GuardDutyの有効化
Terraformでの有効化
本連載で構築してきたterraform/environments/dev/main.tfにGuardDutyの有効化設定を追加します。
# terraform/environments/dev/main.tf
resource "aws_guardduty_detector" "main" {
enable = true
finding_publishing_frequency = "FIFTEEN_MINUTES"
}
resource "aws_guardduty_detector_feature" "s3_data_events" {
detector_id = aws_guardduty_detector.main.id
name = "S3_DATA_EVENTS"
status = "ENABLED"
}設定項目の意味は以下のとおりです。
aws_guardduty_detectorのenable = true: GuardDuty検出機能を有効化finding_publishing_frequency: 検出結果をEventBridgeへ通知する頻度。FIFTEEN_MINUTES、ONE_HOUR、SIX_HOURSから選択aws_guardduty_detector_featureリソース (name = "S3_DATA_EVENTS"): S3保護機能を有効化し、S3オブジェクトレベルの操作も分析対象に追加
なお、以前のAWS Provider(v4系)ではaws_guardduty_detector内にdatasourcesブロックを記述する方式でしたが、現行のv5系以降では非推奨となり、データソースごとにaws_guardduty_detector_featureリソースで管理する形式に変更されました。本記事は新方式に従います。
terraform applyを実行すると、対象リージョンでGuardDutyが有効化されます。VPC Flow LogsとDNSクエリログの分析はデフォルトで有効になるため、追加設定は不要です。
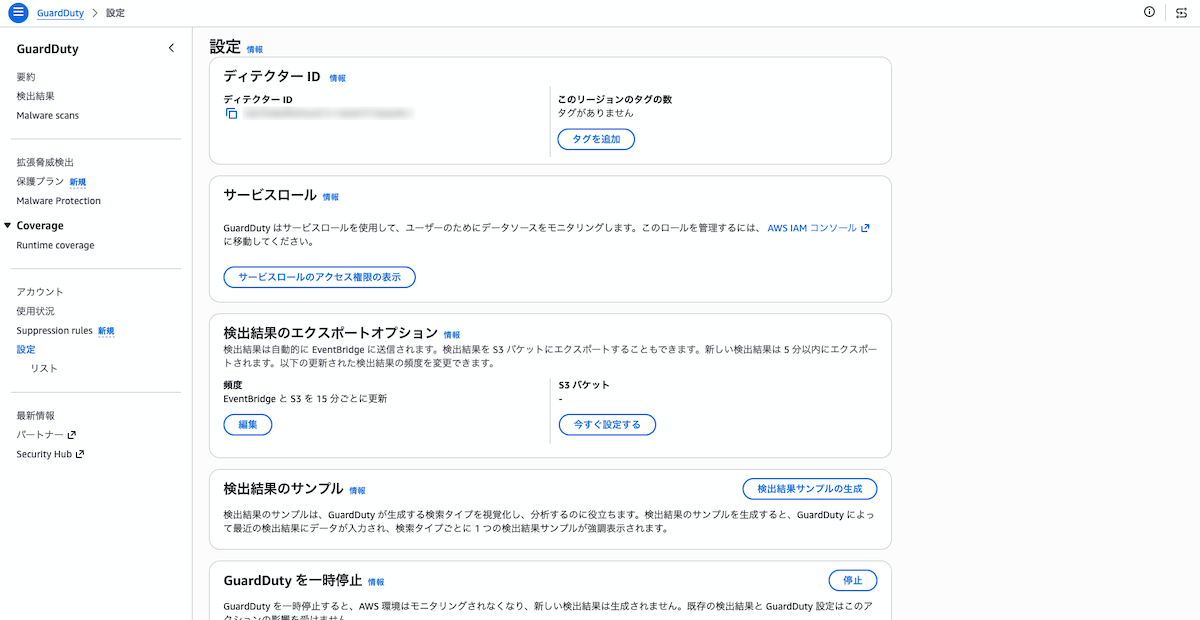
GuardDutyコンソールの「設定」画面を開き、以下の点を確認します。
- ディテクター ID: 値が表示されていればGuardDutyが有効化済み(無効状態では生成されない)
- 検出結果のエクスポートオプション: 頻度が「15分ごとに更新」表示。Terraformで指定した
FIFTEEN_MINUTESが反映されていることを確認 - 「GuardDutyを一時停止」ボタン: ボタンが表示されている=現在稼働中。無効化済みの場合は「GuardDutyを有効化」ボタンに変わる
- 左メニューのS3 Protection: ステータスが有効。
aws_guardduty_detector_featureのS3_DATA_EVENTSが反映されていることを確認
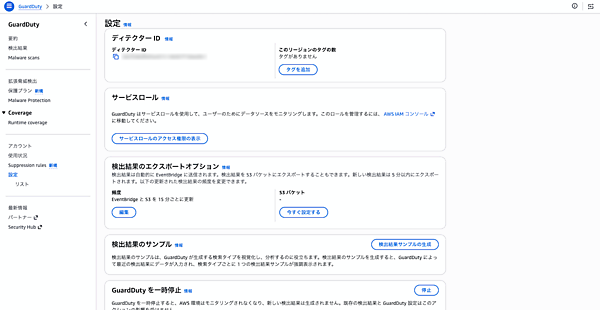
GuardDuty設定画面で有効化と通知頻度を確認 マルチリージョン有効化の考え方
GuardDutyはリージョンごとに有効化が必要です。マルチリージョン環境では、利用していないリージョンも含めて全リージョンで有効化しておくことを推奨します。攻撃者は監視されていないリージョンを狙ってリソースを作成することがあるためです。
複数リージョンに対応する場合は、以下のようにproviderエイリアスとモジュールを組み合わせて構成します。
# terraform/environments/dev/providers.tf
# デフォルトプロバイダ(東京)
provider "aws" {
region = "ap-northeast-1"
}
# エイリアスプロバイダ(他リージョン分を定義)
provider "aws" {
alias = "us-east-1"
region = "us-east-1"
}
# terraform/environments/dev/main.tf
# GuardDutyの設定をモジュール化して呼び出す例
module "guardduty_ap_northeast_1" {
source = "../../modules/guardduty"
providers = {
aws = aws
}
}
module "guardduty_us_east_1" {
source = "../../modules/guardduty"
providers = {
aws = aws.us-east-1
}
}
本記事では、シンプルにするためdev環境の単一リージョンで進めます。
サンプル結果での動作確認
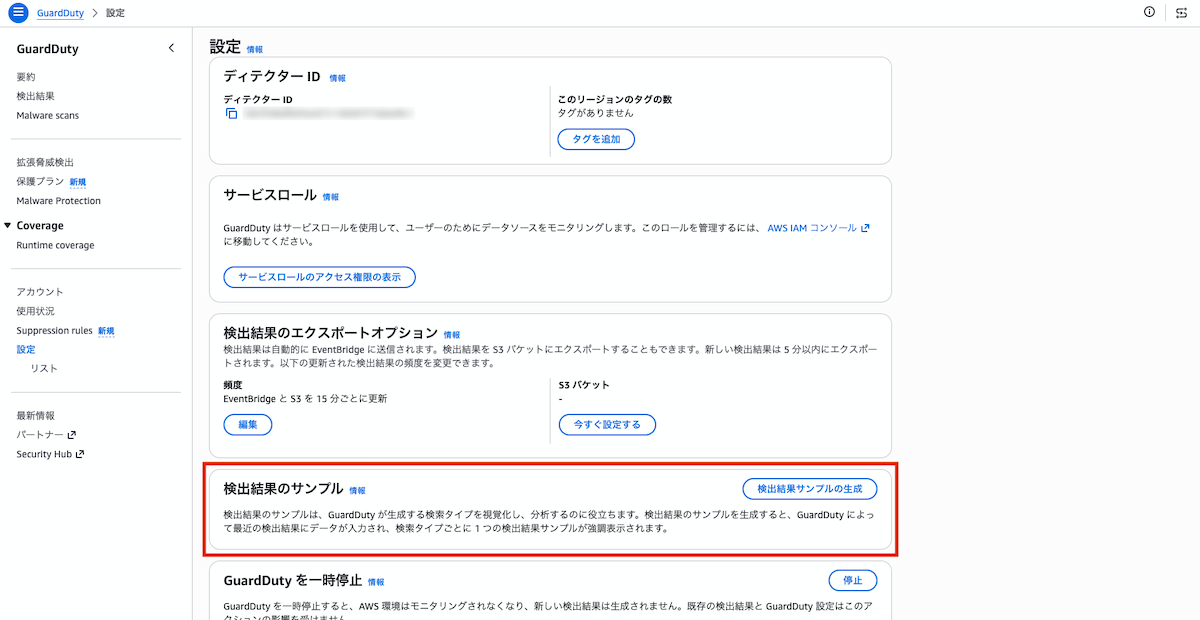
GuardDutyは有効化直後は検出結果がない状態です。動作確認のために、AWSが用意しているサンプル結果(Sample Findings)を生成します。サンプル結果は実際の脅威ではなく、各検出タイプの形式を確認するためのダミーデータです。
GuardDutyコンソールで左メニュー「設定」を開き、「検出結果のサンプル」セクションの「検出結果サンプルの生成」ボタンをクリックすると、検出タイプごとにサンプル結果が生成されます。
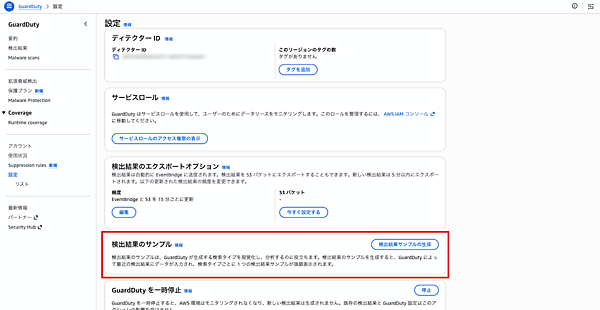
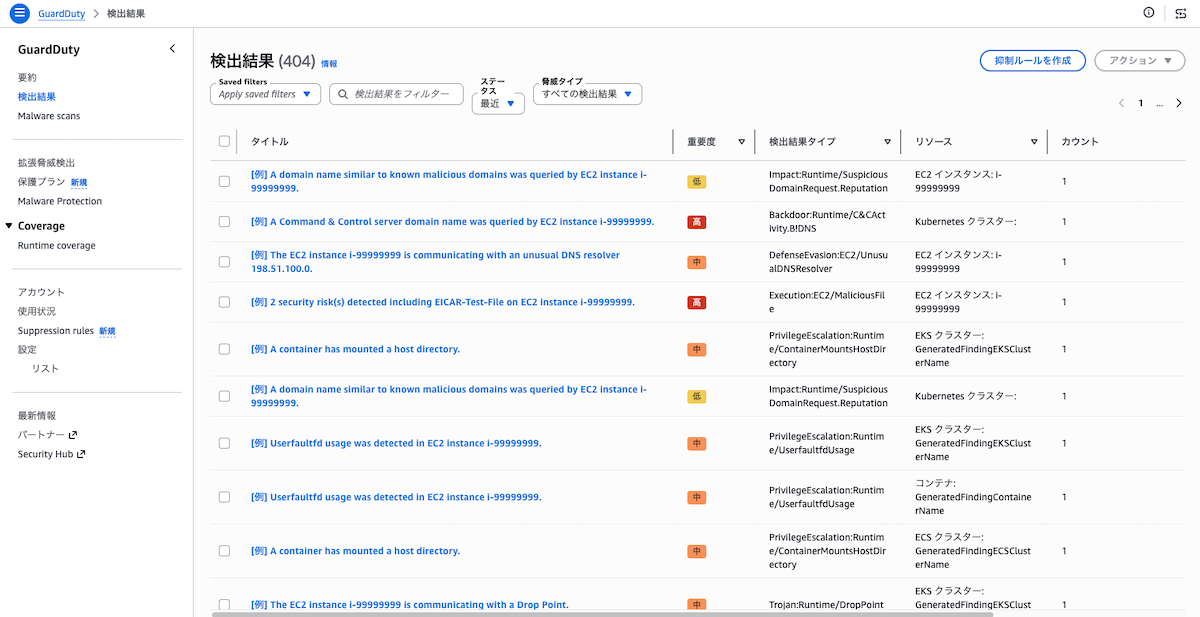
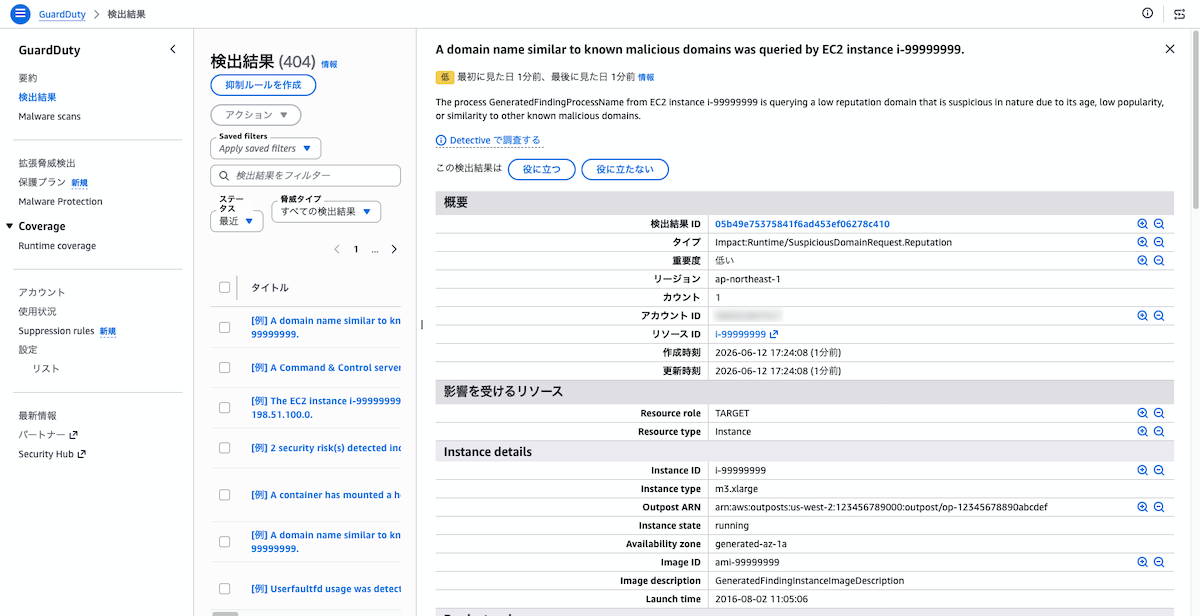
サンプル結果の生成 生成後、「結果」画面に各検出タイプのサンプルが一覧表示されます。重要度、検出タイプ、リソース、最終確認時刻などが確認できます。
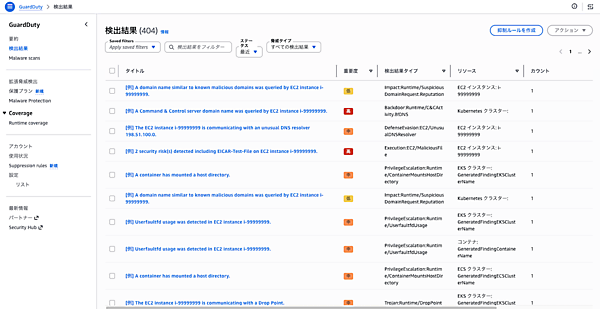
検出結果の一覧 任意の結果をクリックすると、詳細情報が表示されます。検出の概要、影響を受けたリソース、リソース詳細(インスタンスID・イメージID・起動時刻など)が確認できます。検出タイプによっては関与したIPアドレス、ドメイン名、対象API操作なども表示されます。
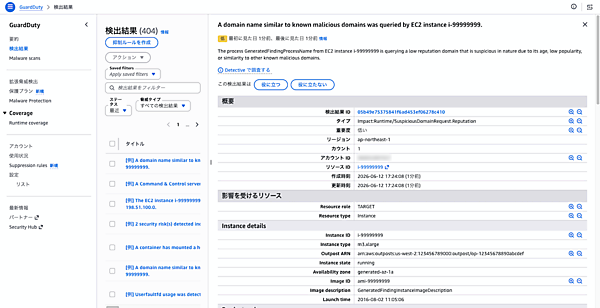
検出結果の詳細 検出結果のSlack通知連携
GuardDutyの検出結果を運用フローに組み込むため、Slackへ自動通知する仕組みを構築します。第24回で構築したAmazon SNS+Amazon Q Developer(旧AWS Chatbot)の構成を再利用します。
全体構成
通知の流れは以下のとおりです。
GuardDuty → Amazon EventBridge → Amazon SNS → Amazon Q Developer → Slack
GuardDutyの検出結果はEventBridgeに自動連携されるため、EventBridgeルールでSNSトピックへ転送するだけで通知パイプラインが完成します。
EventBridgeルールとSNS連携
第25回で作成したsecurity-alertsSNSトピックを通知先として再利用します。main.tfに以下を追加します。
# terraform/environments/dev/main.tf
resource "aws_cloudwatch_event_rule" "guardduty_findings" {
name = "guardduty-findings"
description = "Forward GuardDuty findings to SNS"
event_pattern = jsonencode({
source = ["aws.guardduty"]
detail-type = ["GuardDuty Finding"]
detail = {
severity = [
{ numeric = [">=", 4.0] }
]
}
})
}
resource "aws_cloudwatch_event_target" "guardduty_to_sns" {
rule = aws_cloudwatch_event_rule.guardduty_findings.name
target_id = "SendToSNS"
arn = aws_sns_topic.security_alerts.arn
}
resource "aws_sns_topic_policy" "security_alerts_eventbridge" {
arn = aws_sns_topic.security_alerts.arn
policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Effect = "Allow"
Principal = { Service = "events.amazonaws.com" }
Action = "sns:Publish"
Resource = aws_sns_topic.security_alerts.arn
}]
})
}
event_patternのseverityフィルターで重要度4.0以上(Medium以上)の結果のみ通知対象としています。GuardDutyの重要度は1.0〜8.9の範囲で、4.0〜6.9がMedium、7.0以上がHighです。Low(1.0〜3.9)まで通知するとノイズが多くなるため、運用初期はMedium以上を推奨します。
SNSトピックポリシーでEventBridgeからのPublishを許可する設定も必要です。これを忘れるとイベントは届きません。
Amazon Q Developerの設定
Amazon Q Developerは第24回で設定したsecurity-alertsトピックを購読する設定をそのまま利用します。新規にトピックを購読する場合は、AWSコンソールから対象トピックを追加します。
通知のテスト
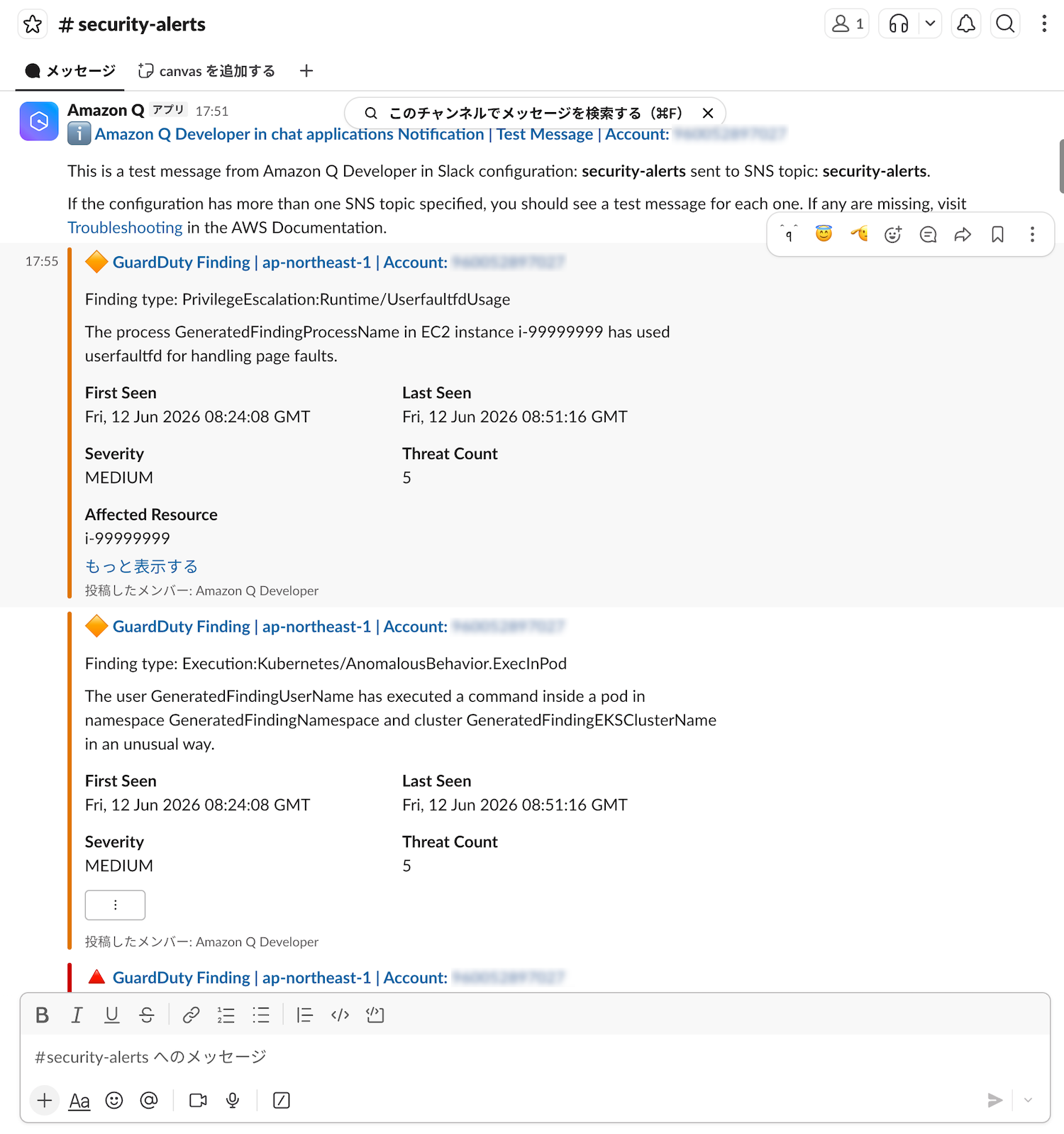
設定完了後、再度GuardDutyのサンプル結果を生成すると、Medium以上の検出結果がSlackチャンネルに通知されます。
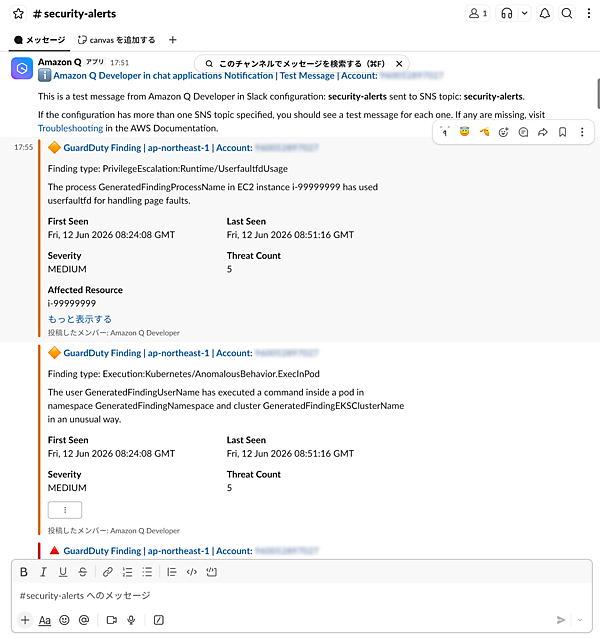
Slackで受信したGuardDuty通知 通知には検出タイプ、重要度、対象リソース、AWSコンソールへの直接リンクが含まれます。担当者はリンクから即座に詳細を確認できます。
運用上の注意点
サンプル結果の削除
サンプル結果は実際の脅威ではないため、検証完了後はGuardDutyコンソールから「アーカイブ」操作で一覧から除外します。アーカイブされた結果は履歴として残るものの、アクティブな対応対象からは外れます。
重要度に応じた対応フロー
GuardDutyの検出結果は、重要度ごとに対応の温度感を変えることを推奨します。
- High(7.0以上): 即時調査。認証情報のローテーション、該当リソースの隔離など
- Medium(4.0〜6.9): 当日中に調査。誤検知の可能性も考慮しつつ、操作元の妥当性を確認
- Low(1.0〜3.9): 定期レビュー。傾向分析の対象とし、即時対応は不要なケースが多い
検出結果と運用ログの突合
GuardDutyが脅威を検出した際、前回構築したCloudTrailのイベント履歴と突合することで、攻撃の前後の操作を把握できます。GuardDutyの「対応の根拠」だけでは情報が不足する場合、CloudTrailにより同時刻帯の他の操作を確認することで影響範囲を特定できます。
おわりに
本記事では、Amazon GuardDutyを有効化し、検出結果をSlackへ通知する仕組みを構築しました。
CloudTrail(第25回)が操作ログの「記録」を担うのに対し、GuardDutyは記録されたログを機械学習で分析する「検知」を担います。両者を組み合わせることで、異常の検出と原因の追跡を一連の流れで実施できます。またEventBridgeを経由してSlackへ通知することで、検出から対応までのリードタイムも短縮できます。
ここまでの連載で、以下の運用基盤が整いました。
- 可視化: Cost Explorerでコストを可視化(第23回)
- アラート: CloudWatch Alarmsでインフラ状態を監視(第20回・第24回)
- 記録: CloudTrailで操作ログを記録(第25回)
- 検知: GuardDutyで脅威を自動検知(本記事)
ただし、GuardDutyは「脅威の検知」に特化したサービスです。AWS環境全体のセキュリティ状態を俯瞰し、ベストプラクティスへの準拠度を評価するには、別のサービスが必要になります。
次回(第27回)は、「AWS Security Hub」を活用してGuardDutyを含む複数のセキュリティサービスの検出結果を集約し、「CIS AWS Foundations Benchmark」などのコンプライアンスチェックをまとめてダッシュボードで確認する仕組みについて解説します。
この記事をシェアしてください
関連記事
「AWS CloudTrail」でAWSアカウントの操作履歴を記録・監視してみよう
6月2日 6:30
「GitHub Actions」で「Terraform」を使用してCI/CD統合を試してみよう
1月6日 6:30
「Terraform」でコードをモジュール化して、環境を分離することで適切に管理しよう
2025年11月25日 6:30
「CloudWatchアラーム」でシステムの問題を自動検知しよう
2月17日 6:30
クラスターを詳細監視する「Container Insights」のセットアップと有効化【前編】
3月10日 6:30
「Terraform」で状態ファイルに「リモートバックエンド」を設定してみよう
2025年12月16日 6:30
バックナンバー
この記事の筆者

筆者の人気記事
「Terraform」のコードを自分で書けるようになろう
2024年5月7日 6:30
WSLとWindowsの設定ファイルを「chezmoi」を使って安全に管理しよう
2025年2月19日 6:30
バージョン管理を柔軟に! プロジェクト単位で「asdf」を使いこなす
2025年5月7日 6:30
インフラエンジニアの視点で見る、DevOpsを実現するためのツールとは
2023年5月16日 6:30
CI/CDを実現するツール「GitHub Actions」を使ってみよう
2024年6月27日 10:13
WSLで「direnv」を活用してプロジェクト単位で環境変数を管理しよう
2025年5月27日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
