はじめに
前回まで、2回にわたってGoogleとMicrosoftのAIプラットフォームで提供されているサービスを説明しました。今回は、韓国の囲碁プロを破ったAlphaGoより20年も昔にロシアのチェス世界チャンピオンを破ったDeep Blueを開発したIBM、ECとクラウドの王者Amazon、この2つのビッグカンパニーのAIサービスを紹介します。
IBM Watson
IBMのAI、Watsonは2011年にアメリカのクイズ番組「ジョパディ」でクイズ王に勝利し賞金100万ドルを獲得して一躍有名になりました。IBMはAIを“Artificial Intelligence”(人工知能)ではなく、“Augumented Intelligence”(拡張知能)と定義付けており、Watsonを「Cognitive Computing System」と呼んでいます。なぜ、それほどAIの呼び名にこだわったのか不思議なのですが、Cognitive Computingという言葉はアメリカでよく使われています。
第3回でGoogleとMicrosoftを比較した表にIBMとAmazonの機能を当てはめてみました(表1)。WatsonはCognitive Computingを謳っているだけあって、自然言語理解(NLU)の部分に細かくAPIが集中しています。
これまでGoogleやMicrosoftに比べてIBMは高いという印象を持っていたのですが、2017年10月に急遽「11月からWatsonの基本的なサービスを無料で提供する」と発表したのでびっくりしました。実際は、無料なのはあくまでも開発者向けで、トライアル期間をこれまでの1ヶ月から無期限にしたというような内容だったのですが、AmazonやGoogle、Microsoftなども開発者向けの無料トライアル枠を設けており、技術者の囲い込み競争も激化しています。
では、コグニティブ・コンピューティングに注力するIBMのWatsonにはどのようなサービスがあるのか見てみましょう。
表1:IBM WatsonとAmazon
| IBM | Amazon | |
|---|---|---|
| クラウドサービス | Watson Developer Cloud | Amazon Web Services |
| 機械学習サービス | Amazon Machine Learning Amazon SageMaker AWS Deep Learning AMI |
|
| 機械学習エンジン | ||
| 画像/動画分析 | Visual Recognition(画像認識) | Amazon Rekognition(画像認識) |
| 音声認識 | Speech to Text(音声認識) Text to Speech(音声合成) |
Amazon Transcribe(音声認識) Amazon Polly(音声合成) |
| 機械翻訳 | Language Translator(翻訳) | Amazon Translate(機械翻訳) |
| 自然言語処理 | Natural Language Classifier(自然言語分類) Natural Language Understand(テキスト分析) Conversation(会話) Retrieve and Rank(全文検索) Document Conversion(文書変換) Personality Insights(性格分析) Tone Analyzer(トーン検出) |
Amazon Comprehend(自然言語処理) |
| ナレッジ | Discovery News(ニュース情報) | |
| 検索 | Discovery(ドキュメント検索) | |
| エージェント・Bot | (Conversationを利用) | Amazon Lex(Alexa) |
| ライブラリ (フレームワーク) |
MXNet |
(1)画像認識(Image Recognition)
Visual Recognitionは画像認識サービスです。ホームページのデモで、第3回のGoogle Cloud Visionで試したスケート写真をアップしたところ、age 18-24というように年齢も検出されていました(図1)。Score(信頼性)が0.39とかなり低いですが、Watson君なかなか見る目がありますねぇ…(笑)。
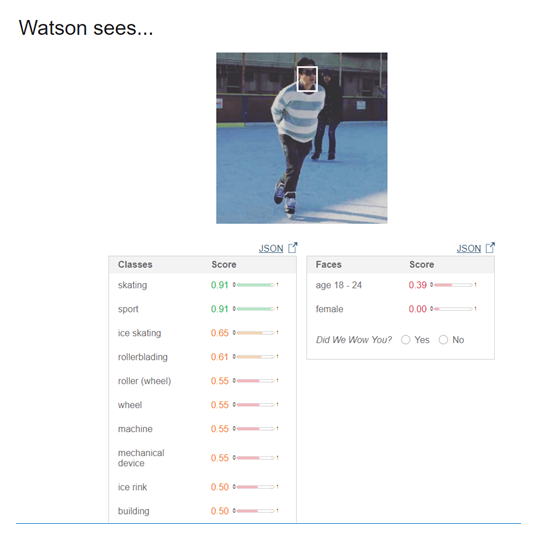
図1:Visual Recognitionにスケート写真を認識させてみた
(2)音声認識(Speech to text)/音声合成(Text to Speech)
Watsonの音声合成のデモでは日本語にも対応しており、Emiさんという女性の声でテキストを読み上げてくれます。比較的長文にも対応しているので他社のサービスと比べてみてください(とてもなめらかに喋ってくれますが、ちょっとイントネーションが違う部分があり、少し方言があるみたいな印象です)。
(3)機械翻訳(Translator)
Watson Language Translatorのデモでは、Conversational、News、Patentという3つのドメインが用意されています。Conversationalはまだ日本語をサポートしてなかったので、Newsで前回やった「ちょっと喋って変換精度を確認してみてください」というテキストの翻訳を試してみると次のような結果になりました。
<<翻訳デモの結果比較>>Input「ちょっと喋って変換精度を確認してみてください」
Google:Please speak a bit and check the conversion accuracy.
Watson:Try sure chatting a little conversion precision
この例だけ挙げるとやはりGoogle翻訳に軍配が挙がりますが、各社とも現在進行形で猛烈に訓練中なので、ある時点のある文だけ比較しても無意味です。オリンピックまでには各社とも高いレベルを実現できていると思います。
(4)自然言語理解(Natural Language Understand)
・Natural Language Classifier(自然言語分類)
文の意図を解釈し、それが関連するキーワードに信頼度レベルを付けて返します。例えば、ユーザーからのメールが「質問」なのか「クレーム」なのか「感想」なのかのクラス分けするような利用が想定されます。
ホームページのデモでは、天気に関する訓練を積んだNatural Language Classifierが、入力されたテキスト文を解釈して「天気の状態」に関する質問なのか、「気温」に関するものなのかを判定する簡単な例が用意されています。
・Conversation(会話)
自然言語により対話を行うAPIで、3つのコンポーネントから構成されています。これを使ってChat botやエージェントを作成できます。
Intent
Natural Language Classifierの技術を使ってテキストを分類し、そこに含まれる目的(Intent)を理解する。
Entity
テキストからキーワードを抽出して対象となるものを示す。
Dialog
IntentとEntityの組み合わせをノードとして、ノード間のフローを作成して回答の流れを組み立てる。
どのようにChat Botを作っていくのかイメージをつかむために、ホームページのデモを参考に、ぬいぐるみに取り付けられる会話型リボンスピーカー(図2)を開発するとしましょう。このリボンは音声合成機能のほかにヘヴィメタとAKBの歌を歌える前提とします。

図2:ぬいぐるみにスピーカー型リボンを付ける
①Intentの作成
まずは、Intentの作成です。ユーザーの会話の中から”反応しなければならない”意図を定義します。ここではユーザーの会話の中で#起動、#歌う、#停止の意図を感じたときに反応することにします。ユーザーが「ベアちゃん」と話しかけると起動し、「歌って」とか「歌が聴きたい」などと言えば歌い、「バイバイ」とか「おやすみ」と言えば停止するわけです。
ポイントはAIの自然言語理解を使っていることで、例文(表1)で設定した語句に完全一致、部分一致せずとも、「また歌って欲しいなぁ」「歌を聴きたいなぁ」といった会話でも意図を拾って反応してくれるようになります。
表2:Intentの作成
| Intent | 例文 |
|---|---|
| #起動 | ベアちゃん |
| #歌う | 歌って 歌が聴きたい |
| #停止 | バイバイ おやすみ |
②Entityの作成
次はEntityの作成です。Entityを定義すると、Intentに反応したときに画一的な反応ではなく会話に合わせて応答内容を変えることができます。例えば、「ベアちゃん おはよう」で起動した場合は「おはよう」とか「Good Morning」とか朝の挨拶で応えたいし、「ベアちゃん 元気?」で起動したときは朝かどうか不明なので「やっほー」と返したい。
また、「歌って」という意図に反応したときに、ヘヴィメタを歌って欲しいのか、AKBを歌って欲しいのか、なんでもいいのかの意図をつかみたい。そして、分からなかった場合は聞き返したい。このような反応を分岐させるための選択ポイントがEntityで、選択肢が対象(キーワード)です。ここでは、表3の5つのEntityを作成しておきます。
表3:Entityの作成
| Entity | 対象(キーワード) |
|---|---|
| @Hello | おはよう、こんにちは、元気 |
| @歌 | 何か、ヘヴィメタ、AKB |
| @ジャンル | ヘヴィメタ、AKB |
| @ジャンル_それ以外 | 童謡、Jポップ、演歌 |
| @GoodBy | おやすみ、バイバイ、またね |
③で会話フローを組み立てる
IntentとEntityを作成したら、この2つの組み合わせを使ってノードを作成し、Dialog(ノードのフロー図)を作成します(図3)。図の最初のノードは#起動Intentに反応するノードで、会話の中に「元気」というキーワードが含まれている場合の反応を定義しています。ノードの下側はWatsonが返す回答で、ここでは「ヤッホー。元気だよ!」と応えています。
ユーザーの会話に「歌う」意図が感じられた場合は、2つ目の#歌うIntentに来ます。そこで応答した内容に対するユーザーの反応を待つ場合は、ノードは右側に遷移します。ここではEntityで定義した@ジャンルと@ジャンル_それ以外に関するキーワードをもらった場合にそれぞれの反応を行います。会話らしく相手の言葉を含めて応答できるように、Watsonの反応(下欄)にはユーザーが発したキーワードも入れられます。
なお、ユーザーの発した言葉から意図が拾えなかった場合の処理はAnything elseノードで定義します。ここでは、「いい気分、ヘヴィメタ歌いたいなぁ」とつぶやいてユーザーの反応を待ちます。

図3:Dialogで会話を組み立て、Try it Outで確認
④Try it Outで会話を確認する
Conversationには、Try it Outという会話を確認できるボードが用意されています。これを使って、より自然な会話となるようにDialogを改良し続けることになります。実際にはもう少し複雑なフローを作成できるのですが、とりあえずここでは会話の組み立てイメージを理解できればよしとします。このようにChat botはロジックの組み立てで会話らしくしているわけですが、話しかけの中のIntent(意図)を理解する部分に自然言語理解(NLU)が使われています。
・Retrieve and Rank(機械学習を使った全文検索)
Retrieve and RankのRetrieveは検索する、Rankはランクアップの意味です。つまり、機械学習機能により、対象データに適合した検索を行えるように訓練することを指したネーミングになっています。Apache Solr(アパッチ・ソーラー)を利用した検索サービスなのですが、機械学習機能によりSolr標準の検索よりもヒット率の高い検索を行います。
なお、Retrieve and RankとDocument Conversionは下記のDiscoveryに統合されることになり、サービスの廃止が発表されました。
Apache Solrはオープンソースの全文検索システムです。形態素解析を利用した全文検索のほか、同義語検索や類似検索、関連度検索などかなり高度な検索が行えます。検索エンジンだけでなく管理画面も用意されており、企業内のデータ検索(エンタープライズサーチ)などで使われています。
テキストから文字列を検索するのにgrepをよく使うと思います。これは順次走査検索なので、予めインデックスを作成する必要はないのですが、検索対象データが膨大になると検索速度が遅くなります。
検索を高速にするにはインデックスを作成する必要がありますが、日本語の場合は英語と違い単語と単語の間にスペースが入らないためインデックス化が難しく、これまではn-gramや形態素解析という手法が使われていました。
n-gramは検索対象の文章を単語単位ではなく文字単位で分解し、n文字ずつ分割したインデックスを作成する方式です。例えば、”形態素解析”という文字列をn=2(バイグラム)で処理すると”形態””態素””素解””解析”というインデックス化が行われます。これらを検索する場合、検索文字列もバイグラム単位で分解します。例えば、”自由形態素”という検索キーワードの場合は”自由””形態””態素”というように分解して検索するわけです。この方式の弱点は検索ノイズが多いことで、例えば単純に使うと”形態素”で検索したのに”形態”という単語を含む文を全部拾ってきてしまいます。
形態素解析は解析用の辞書を用意し、それを使って文脈から単語を検出してインデックスを作成する方法です。代表的なところでは、Namazuというフリーの全文検索エンジンがMeCabという分かち書き機能を使って形態素解析をしています。この方法はn-gramに比べてノイズを拾いにくいのですが、辞書の品質を高くしないと検索漏れが生じるため、辞書の作成やメンテナンスが大変です。
そこで機械学習を使う手法が登場しました。訓練データから対象データの検索に適した機械学習モデル(Rank)を作成し、最適化されたインデックス付きドキュメントを出力します。機械学習なので、教えていない検索データでもうまい塩梅に検索してくれます(良い学習ができていればの話ですが)。
・Discovery(ドキュメント検索)
大量のドキュメントから必要なものを見つけてくれるドキュメント検索クエリーです。WordやPDF、HTML、JSONなどのドキュメントを取り込んで、文章の内容をテキスト分析してインデックスを付け、検索キーワードに適したものを抽出してくれます。検索キーワードは話し言葉でもOKで、自然言語処理(NLP)をカスタマイズすることもできます。
膨大なドキュメントから必要なものを検出するニーズは高いので、AIを使ったドキュメント検索は今後大きく伸びそうな分野です。企業内のドキュメントはもちろんのこと、ネット上の情報を集めてナレッジ化し、DiscoveryのようなAI検索で精度の高い(ヒット率の高い)情報取得を行えるサービスが増えると思われます。
例えば、米国ではデータベース化したナレッジに対して、AI技術を使って膨大な裁判事例データの中から今回の事案に役立つデータを検索するサービスが幅広く利用されています。また、研究機関では特許情報や論文などの文献の中から、必要な情報を見つけ出すサービスもあります。
・Discovery News(ニュース情報サービス)
前回、Microsoftが行っている”ネット上の情報を集めてナレッジ化する”モデルとしてMicrosoft Academic Graph(MAG)を紹介しましたが、IBMもWatson Discovery上に世界中のニュースを収集して情報サービスとして提供しています。
・Document Conversion(文書変換)
例えば、Retrieve and Rankのようなサービスを使ってドキュメントを検索する場合、ファイルフォーマットがバラバラだと検索が難しくなります。Document ConversionはWordやPDF、HTMLといった文書を検索しやすい形式(JSON、テキスト、HTML)に変換できるので、この変換処理を通してRetrieve and Rankサービス用に文書を準備します。
・Personality Insights(性格分析)
採用面接のSPI試験では言語能力や数学的能力のほかに「性格」も診断されているって知っていますか。「チャレンジ精神旺盛だけどあきらめも早いタイプ」とか「人前で話すのは少し苦手だけどコツコツやるタイプ」など、まるで自分のことをよく知っているかのような解説も付くのですが、これが意外と重視されており性格診断の結果が悪いと成績が良くても落されるケースが多いようです。
Personality Insightsは設問からでなく、本人が書いた文書から性格診断を行うものです。応募申込時に「今の日本の現状と10年後の展望」などの課題を出して、悲観的なことを書いたら「後ろ向きの性格で、物事をクヨクヨと考えがち」などと判定されてしまうかも知れません 。
こうした応募書類なら構えて書くでしょうが、ツイッターのつぶやきを拾われて性格診断されるとしたら、おいそれとネガティブなことも欠けませんね。実際にホームページのデモでは、ダルビッシュ有選手のツイッターコメント@faridyuをベースとした性格診断結果が出ていました。
なんと、自分のツイッターアカウントでも診断できるようです。試しに自分のツイッターアカウント@umedanoで性格判断」してみると…。ふむふむ、「知的好奇心100%」「外向性98%」「変化許容性97%」などが顕著で、「感情起伏54%」「現状維持1%」「快楽主義0%」などが低い。これを見ると結構当たっているような気もします。Watson君おそるべし!
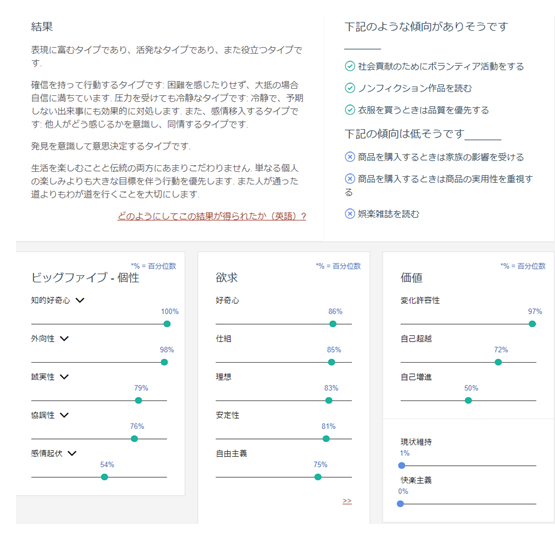
図4:Personality Insightsによる自分の性格診断
・Tone Analyzer(感情分析)
Personality Insightsが文書から性格を診断するものなら、こちらは文書から書き手の感情を分析するAPIです。文ごとにリアルタイムに感情を分析し、怒りや不安、喜び、悲しみ、嫌悪などを検出します。
例えば、カスタマーサポートセンターの電話やメールのやり取りで顧客およびオペレータの感情をモニタすれば、顧客が激高したりオペレータが傲慢な回答をしたりしている電話やメールをキャッチ&表示できます。Chat Botやパーソナルアシスタントなどの応答でお客様の感情を分析しながら、適切に対処するようにプログラムすることにも役立ちます。
また、通話記録やメール、Web問い合わせでの応答を後でまとめてレビューするような場合でも、膨大なデータの中からチェックすべきやり取りを自動的にピックアップするのに役立ちます。
Amazon
Amazonの強みは、クラウドサービスとECサイトの両方で世界一だということです。そしてもう1つ、「Amazon Echo」というBluetoothのスマートスピーカーを世界に先駆けて発売して成功していることも注目に値します。AmazonはAIに関して少し出遅れましたが、これらの強みを生かした展開をしています。特に、下記のAIサービスは背景にAmazon Echoの成長・発展が感じられるものです。
(1)パーソナルアシスタント
2014年末に発売されたAmazon Echoは、音声で操作できるスピーカーというだけでなく、天気やニュース、交通情報などさまざまな情報を教えてくれます。また、Uberの配車やピザの注文などもできるようになっています。
この音声インタフェースを実現するために組み込まれたパーソナルアシスタントがAmazon Alexa(アレクサ)で、音声認識、音声合成、自然言語理解(NLU)などの機能によりChat Botのような会話も楽しめます。
なお、Amazon Echoの大ヒットを受けて、小型サイズの「Amazon Echo Dot」、持ち運び可能な「Amazon Echo Tap」、カメラ機能の付いた「Amazon Echo Look」、ビデオ電話や液晶ディスプレイの付いた「「Amazon Echo Show」などが次々と発売されています。
(2)Chat Bot
Amazon Lexは、Alexaに採用されているパーソナルアシスタント機能をさまざまなアプリケーションや製品で利用するためのマネージドサービスです。
(3)音声合成(Text to Speech)
Amazon PollyにはJavaや.Net、Pythonなどのプログラミグ言語やAndroid、iOSなどのプラットフォームに合わせたAPIが用意されており、さまざまなアプリケーションから利用できます。ホームページのデモでは、日本語はMizukiという女性の声のみでしたが、最近になってTakumiという男性の声も登場しました。なかなか自然な音声なのでWason君と聴き比べてみてください。
(4)機械学習サービス
どんな技術でも最初は高度なスキルを持った人が面倒な手続きを駆使して行う段階があり、その後より簡単に利用できる仕組みが提供されて裾野が広がっていきます。Amazonもそうした流れを捉えて、11月末のAmazon re:Inventカンファレンスで機械学習モデルを作成するためのマネージドサービスSageMakerを発表しました。
これは機械学習モデルの制作プロセスをトータル管理するプラットフォームで、エンジニアやデータアナリストは今までよりも簡単に機械学習モデルを作成することができます。なお、Sageとは「賢者」の意味で、なるほどというネーミングですね。
パーソナルアシスタントとスマートスピーカー
Googleの「Google Now」、Appleの「Siri」、Microsoftの「Cortana」、Amazonの「FAlexa」など、各社のパーソナルアシスタント機能がかなりレベルアップしてきました。音声認識からChat Bot、そしてパーソナルアシスタントとAI的な総合力が増してきて、これらを組み込んだスマートスピーカーのバトルもヒートアップしています(表4)。
ハードウェアにAIを搭載という動きはこれからも広がりそうです。音声AIがスピーカーなら画像AIはカメラです。今年10月にGoogleがAI搭載カメラGoogle Clipsを発表したのに続いて、Amazonもre:InventカンファレンスでAWS DeepLensというビデオカメラを発表しました。
Google Clipsはユーザーがバッグなどにクリップして持ち運べる普通の(といってもAIがベストショットを判断して撮影する)カメラです。一方、AWS DeepLensは画像認識系AIと学習済モデルが組み込まれたエンジニア(開発者)向けのカメラでカスタマイズも可能です。
SageMakerと同じエンジニア囲い込み作戦で、画像認識AIを学べる手軽なグッズを提供するというちょっと面白いアイデアですね。一般消費者向けのGoogle Clipsに比べると台数は出ないと思いますが、きっちり同じ価格の249$というのが笑ってしまいます。
これからもパーソナルアシスタントの知性はますます発達するでしょう。と同時にハードウェアも著しく進化を遂げることにより、”一家に1台AIロボット”という時代が遠からず来そうな雰囲気です。
表4:主要企業のパーソナルアシスタントとスマートスピーカー
| パーソナルアシスタント | スマートスピーカー・家庭ロボット | |
|---|---|---|
| Google Now(OK Google) | Google Home | |
| Apple | Siri | Apple Home Pod |
| Microsoft | Cortana | INVOKE(HARMAN KARDAN製) |
| Amazon | Alexa | Amazon Echo |
| LINE | Clova | WAVE |
| M(メッセンジャー専用) Wit.ai(オープンソース) |
開発中? | |
| Alibaba | AliGenie | Tmall Genie |
| 小米(Xiaomi) | 小愛同学 | Mi AI Speaker |
| 百度(Baidu) | DuerOS | 小魚在家(Little Fish) |
| 騰訊(テンセント) | Baby Q | |
| Samsung | Bixby | Vega |
今回はIBMとAmazonのAIサービスを取り上げました。次回は、SNSの雄Facebookとスマートデバイスの雄Apple、そしてGPUを武器にハードウェアで圧倒しているNVIDIAのAIプラットフォームを紹介します。それぞれ自社の強みを活かした取り組みが表れていて興味深いものがあります。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
