はじめに
第1回で、Web3という言葉には「P2P分散型ネットワーク」「セマンティックWeb」「メタバース」という3つのテーマが含まれていると説明しました。前回まではブロックチェーンやDAppsなどの分散型ネットワークを解説して来ましたが、今回からはロマンを感じさせられる「セマンティックWeb」編に入ります。
セマンティックWeb
semanticとは「意味の」という英単語です。つまり、semantic webは“意味を持つWeb”ということになりますが、それはどういうものなのでしょうか。図1に通常のWebとセマンティックWebの対比を示したので、この図をもとに説明しましょう。
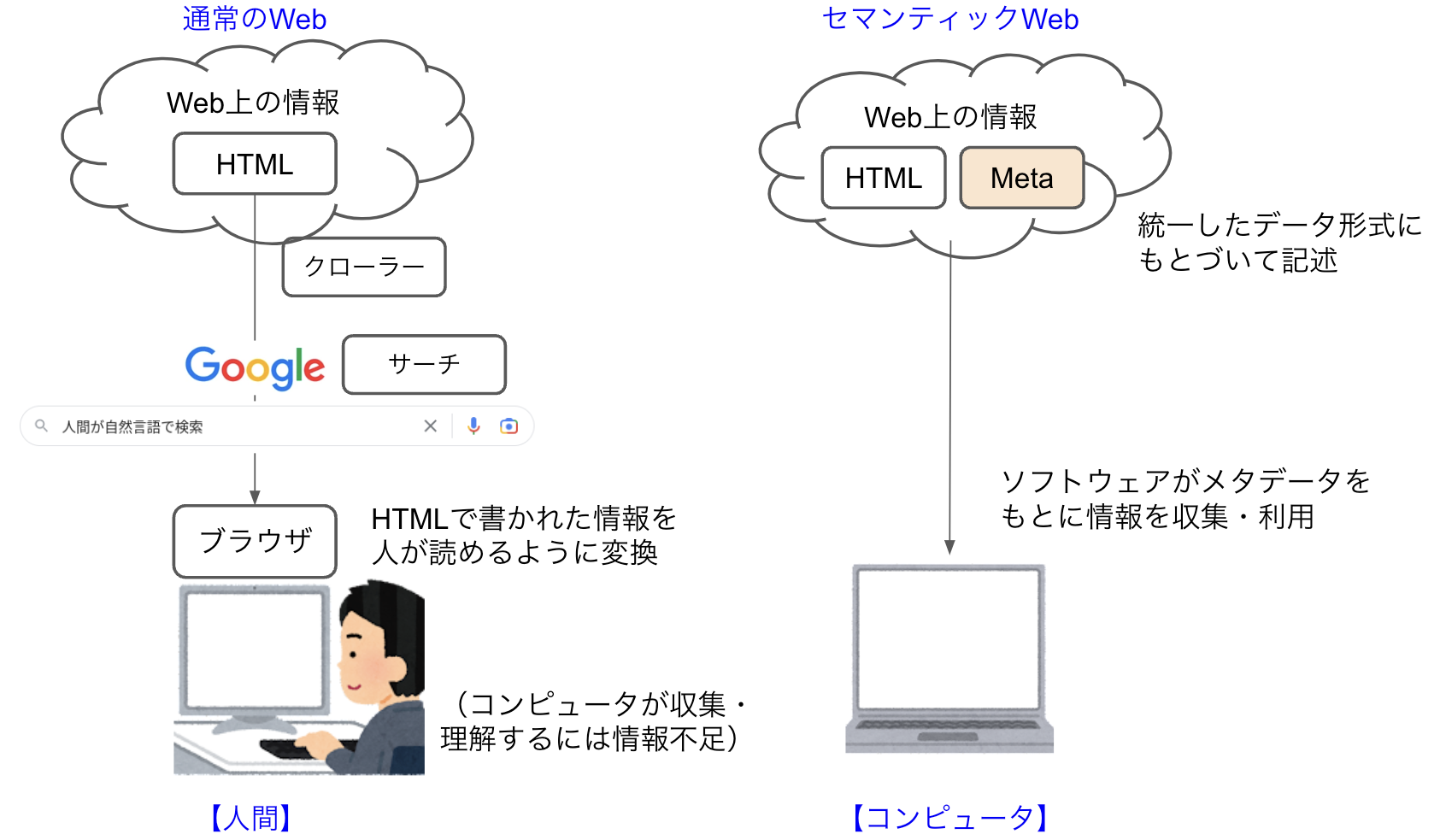
図1:通常のWebとセマンティックWebの対比
通常のWebから取得した情報はただのデータで意味を持ちません。例えば、企業のホームページにアクセスした際に、これが会社名、これが会社の住所というような意味合いは、人間がホームページを解釈して理解するものです。これに対してセマンティックWebは、コンピュータが自律的にWeb上の情報を理解できるように、情報にメタデータを付加する概念です。
メタ(meta)という英単語は“高次の”という意味です。一般の人にはあまり知られていない単語でしたが、facebookが社名をmetaに変更したことで一気に広まりましたね。ただ、これはmetaとuniverse(宇宙)を組み合わせたmetaverse(仮想空間)から取ったもので別の意味です。
我々エンジニアが馴染みがあるのはmeta dataという単語の方ですね。データそのものと次元が違うデータという意味で、一般に「情報についての情報」と言われています。例えばデータベースに格納されている情報が通常のデータだとすると、格納するための仕組みの情報(カラム定義情報など)がメタデータになります。
私たちが慣れ親しんでいる通常のWebは、HTMLで書かれた情報を人間が理解できるようにブラウザが変換してくれています。GoogleクローラーとGoogleサーチのおかげで、私たちは自然言語を使って情報を探すことができますが、コンピュータが自律的にデータを収集して理解するには情報不足です。
これに対してセマンティックWebは、Webの情報が何を表しているかを統一したデータ形式に基づいて記述します。これにより、コンピュータがサイトを横断して求める情報を検索できます。
例えば、みなさんが今読んでいるこの記事はHTMLで書かれています。Googleクローラーとサーチのおかげで「Web3」「セマンティックWeb」「梅田弘之」などで検索すると表示されるかも知れませんが、検索されないかも知れません。この記事にメタデータとしてテーマや著者などの要素(タグ)を定義して「Web3」「セマンティックWeb」「梅田弘之」というキーワードを入れておいたらどうでしょうか。今度は、世界中のデータからコンピュータが求める情報を簡単に入手できるわけです。
ただし、セマンティックWebの本質は意味を伝えるメタデータではありません。世界を1つのグラフデータベースとして、さまざまな種類のデータを扱えるという夢のような構想が実現できる技術なのです。
Layer Cake
セマンティックWebは、www(World Wide Web)を考案し、URLやHTTP、HTMLを設計したティム・バーナーズ・リー氏が1998年に提唱した概念です。バーナーズ氏は1994年にWorld Wide Webコンソーシアム(W3C)を設立し、HTML5やCSS、セマンティックWeb、XMLなどの技術の標準化および普及活動を行っています。
バーナーズ氏がセマンティックWebの説明に使ったのが図2のLayer Cakeです。本当は層を重ねて作るケーキのことですが、セマンティックWebに置き換えるとこのような階層構造になります。セマンティックWebの概念と構造を理解するのにLayer Cakeは非常によくできているので、下の階層から順番に説明していきましょう。まずは、1層目のURIとUnicodeです。
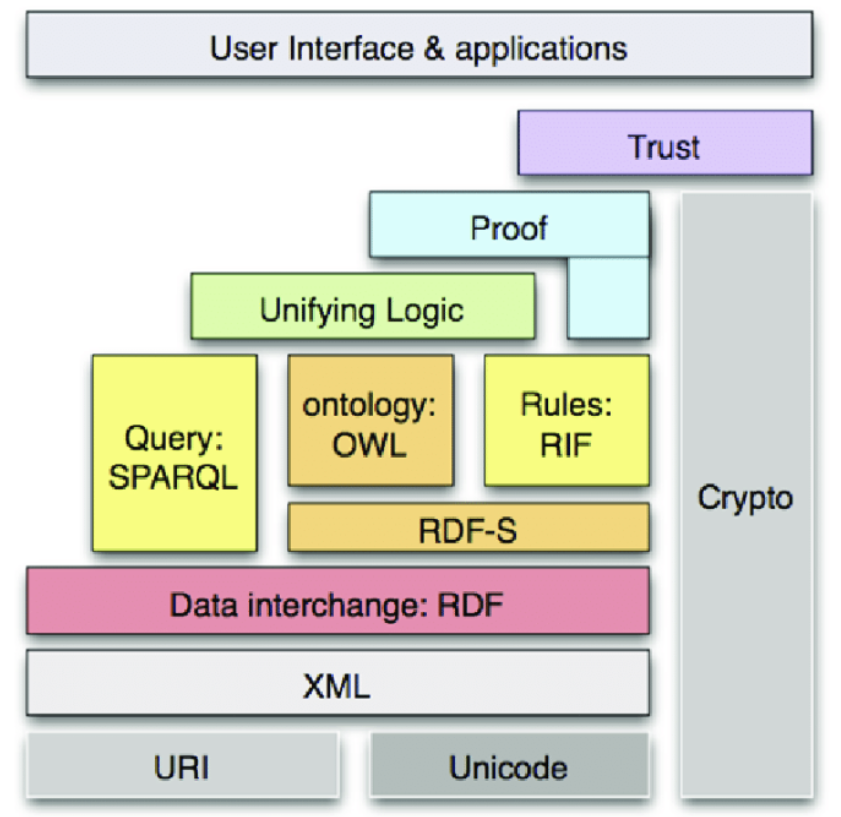
図2:Layer Cake【出典】ReserchGate(Berner-Lee & Swick,2006)
セマンティックWebは本当にすばらしいアイデアです。ただ、25年も前にバーナーズ氏が提唱して2004年前半にはブームになったのに、未だに普及しているとは言えません。理由はいくつか挙げられていますが、メタタグを付与してもメリットがあまり感じられなかったことと、どのようなタグを付ければ良いかが意外と難しいからだと思われます。
しかし、メタデータを付けてコンピュータの可読性を高める考え方は、一部で取り入れられています。W3Cが策定した標準とは違いますが、Googleのリッチスニペットなどは似た概念です。現在「パンくずリスト」や「商品情報」「レビュー・評価」など30種類のスニペットが用意されており、そこに適切なメタ情報を入れるだけで検索結果のクリック率を上げるのに役立っています。
ところで、ここに来てセマンティックWebがWeb3として再び注目されているのはなぜでしょうか。理由は、それが悲願だからです。第1回で「Web3は2014年にギャビン・ウッド氏が提唱した」と述べましたが、これはブロックチェーン技術を中心とした分散型ネットワークを想定したものです。実はそのはるか前の2006年にバーナーズ氏がWeb3.0という言葉を使っており、それはセマンティックWebだったのです。
つまり、もともとWeb3.0はセマンティックWebだと言っていたので、新参者のブロックチェーンがWeb3を語るなら、こっちも含めろという感じなのです。ただし、やみくもに本家ヅラしているわけではありません。セマンティックWebの取り組みはずっと続いて進化もしており、ビッグデータやAIの時代を迎えていよいよ出番だということで注目されていることも事実です。
URI
URI(Uniform Resource Identifier)とは、リソースを識別して名前や場所を示すものです。うん? おなじみのURL(Uniform Resource Locator)と似ていますが、どこが違うのでしょうか。この2つは場合によって同じ意味で使用できますが、表1のような違いがあります。
表1:URIとURLの主な違い
| URI(Uniform Resource Identifier) | URL(Uniform Resource Locator) | |
|---|---|---|
| 識別するもの | リソースの場所(URL)と名前(URN)の両方 | リソースの場所(URL)のみ |
| 使用目的 | XMLやタグ、ライブラリ、ファイルなどさまざまなリソースに使用される | 主にWebページやメールアドレスを検索するために使用される |
| スキーム | プロトコル、仕様、HTTP、ファイル、データなど | HTTPやHTTPSなどのプロトコル |
| ブラウザ | ChromeやEdge、Firefoxなど一般的なブラウザで使用できるが、古いバージョンでURIスキームが未対応の場合がある | 基本的に使用できる |
URLはWebページなどリソースの場所を表すアドレスですが、URIは場所(URL)に加えて名前(URN)も識別します。URIはリソースを一意に識別するので、セマンティックWebでリソースを区別し、情報を解釈するのに役立ちます。URLとURIは次のような関係であり、URLはURIのサブセットです。すべてのURLはURIですが、その逆は必ず成り立つとは限りません。
URI = URL + URN
また、URLがHTTPSなどのプロトコルによってWebページを検索したり、mailto:スキームを使ってメールアドレスを指定するなど限られた目的なのに対し、URIはXMLやタグ、ライブラリ、ファイルなどさまざまなリソースを明確に区別します。これによりコンピュータはWebページとファイルなどの他のリソースを混同することがありません。
・URN
URLはよく知られていますが、URNはなじみが薄いので説明しておきます。URN(Uniform Resource Name)は、リソースを場所に依存することなく識別するIDで、次のような構文で表します。

例えば、urn:isbn:978-4-295-00535-3というスキームは、NID(Namespace Identifier)がisbn、NSSが4つのパートからなる13桁の番号です。このスキームでは、書籍に一意に付けられるISBN番号を使って私の書いた本「エンジニアなら知っておきたいAIのキホン」を識別します。
・URIの構文
URIは、次の構文で表されます。コンピュータはこの構文を解釈してリソースの名前や場所を知ることができるのです。
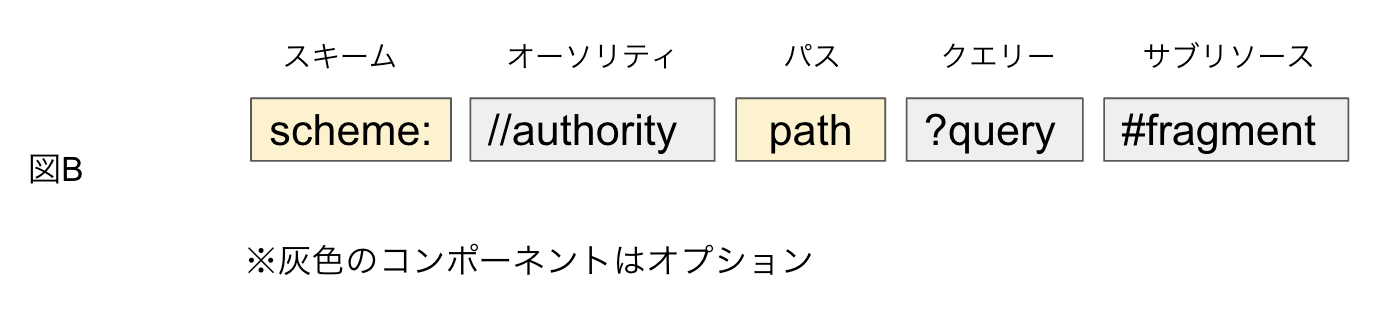
最初のschemeは、リソースに到達するための手段を示すものです。例えば、よく知られている「https:」もURIスキームの1つで“SSL/TSLを使用して保護されたHTTP接続で通信しますよ”ということを表しています。URIスキームはたくさんあり、Wikiにもスキーム一覧が紹介されています。中でも「ftp:」「mailto:」「file:」「git:」などはなじみが多いスキームですね。
authorityは必要に応じて付けられるコンポーネントです。ユーザー名とパスワード、ホストのIPアドレスや登録名、ポートという3つから構成されます。pathはリソースの場所を表す情報、queryはクエリ文字列で、key=値という形式で記述されます。
例えば、下記のようなGooglイメージ検索画面のアドレスの場合、「https:」がスキーム、「//www.google.co.jp」がオーソリティ、「imghp」がpath、「?hl=en&ogbl」がqueryです。
fragmentは、サブリソースを指定する場合に付加される情報で、前に#(ハッシュ記号)を付けて表します。例えば、下記のGmailアドレスの最後がfragmentで、Gmailページのトレイが受信トレイの場合は#inbox、送信済トレイの場合は#sentと切り替わります。
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
