はじめに
前回まで、推論・予測を行う高度なデータ分析を題材に、AI/機械学習が及ぼす業務や組織への影響について見てきました。現段階では、データ準備とモデリングが主な対象ですが、AI/機械学習が自動化するのはそれだけに留まらず、将来はデータ分析の全工程が対象になると考えられます。今後は機械学習の生成物である学習済みモデルの活用機会が増え、迅速で低コストな分析業務の推進に大きく関わってくることとなります。そこで、今回からは学習済みモデルの活用法や注意点を解説します。
学習済みモデルとは
全てのデータ分析工程が自動化されている分析アプリケーションとして、AWS(Amazon Web Services)が提供するAIサービスであるAmazon Personalize(レコメンデーションを行う)やAmazon Forecast(予測を行う)が例として挙げられますが、これらの中核となるのが、学習済みモデルです。
学習済みモデルとは、アルゴリズム(プログラム)と学習済みパラメータを組み合わせたものです。実績データ(学習用データセット)を使ってパラメータの値を変化させてアルゴリズムを実行した結果、最も実用的な精度が得られたものが学習済みパラメータです。図1では、パラメータを1から3まで変化させてアルゴリズムを実行した結果、パラメータが2のときに最も高い精度が得られたので、これを学習済みパラメータとして採用しています。
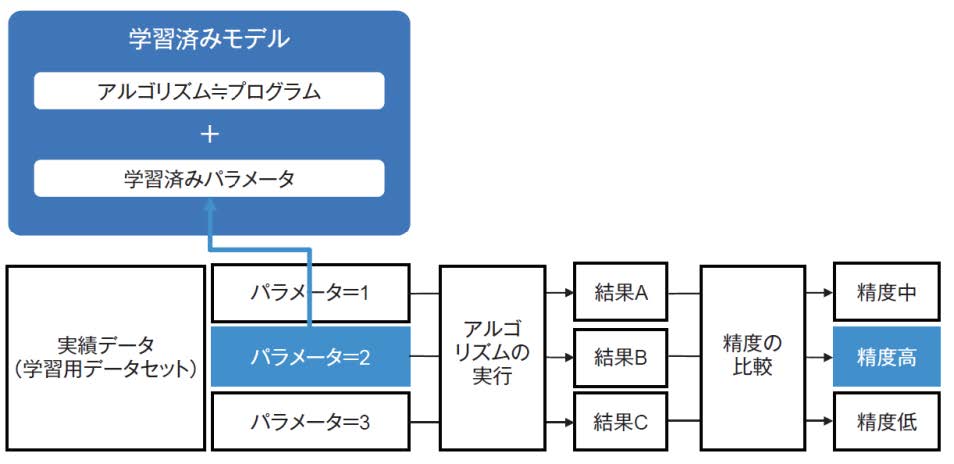
図1:学習済みモデルと学習済みパラメータ【出典】ITR
この学習済みモデルを利用すると、定型的な形式での実績データを与えるだけで、特定の目的にかなった分析結果を高精度で得ることができます。例えば、Amazon Forecastのような予測AIサービスでは、利用者が過去の実績データを投入するだけで、高い精度で将来の予測値を得ることができます。
学習済みモデルを利用した
システム/サービスの特徴
それでは、学習済みモデルを利用したシステムやサービスには、どのような特徴があるでしょうか。
一般的なデータ分析システムは、BIツールやデータマイニング・ツールといった汎用的なソフトウェアを利用するため、特定の分析結果を得るには、開発者あるいはデータ分析担当者が目的に沿ったデータモデリングやプログラミングを行う必要があります。つまり学習済みモデルを利用したシステムやサービスは開発環境、あるいはPaaSのようなものと言えます。
これに対して、学習済みモデルを利用したシステムやサービスの場合、特定の目的に対しては、利用者が実績データを投入するだけで求める結果を得ることができます。つまり、アプリケーション、あるいはSaaSのようなものと言えるでしょう。
したがって、利用者の目的にかなった学習済みモデルを利用したシステムやサービスが存在すれば、開発の必要がないため、導入、展開が速いというメリットがあります。また、本来、導入、展開に必要なSE、プログラマー、データ・サイエンティストといった要員も少人数で抑えられるため、人件費を含めたトータルコストも低減されるというメリットがあります。
しかし、学習済みモデルを利用したシステムやサービスを使用する場合には、根拠の説明と検証は誰が行うのかというユーザーのデータリテラシ(分析結果を理解し、それを説明できる能力)と、従来とは異なるソフトウェア開発方式や契約形態に注意を払う必要があります。
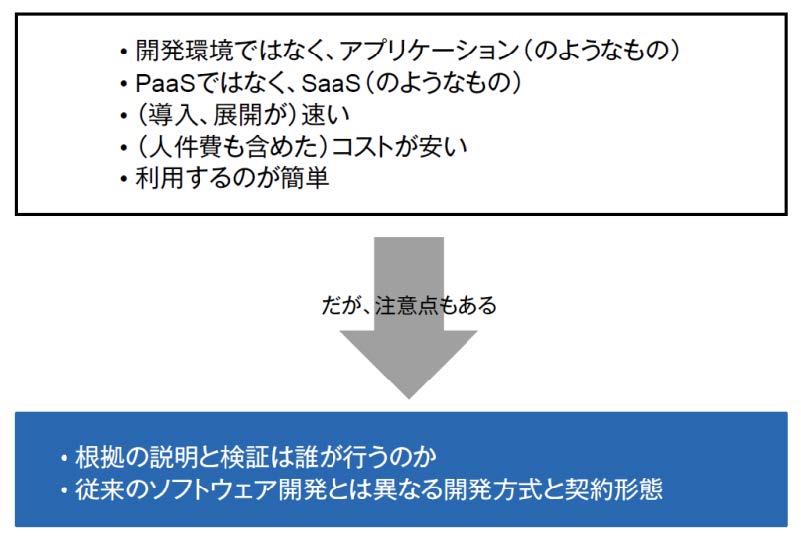
図2:学習済みモデルを利用したシステム/サービスの特徴と注意点【出典】ITR
根拠の説明と検証は誰が行うのか
学習済みモデルを利用したシステム/サービスは、分析工程が全て自動化されているため、一般のエンドユーザーが利用しても結果を得ることができます。しかし、専門知識を持たないエンドユーザーだけで利用した場合、得られた結果の根拠の説明や検証は誰が行うのかという問題が残ります。
例えば、来月の販売数量は約6万個という予測結果が得られた場合、学習済みモデルを利用したシステム/サービスから提供される根拠の説明は図3のようになります。

図3:学習済みモデルを利用したシステム/サービスから提供される根拠の説明【出典】ITR
この情報を正しく理解するためには、少なくとも「単回帰分析」「信頼度」「R2(決定係数)」といった統計学用語を理解していなければなりません。
つまり、学習済みモデルを利用したシステム/サービスにおいては、結果を得るだけであれば何ら専門知識は必要としませんが、得られた結果の根拠を説明し、それが適切であるかどうかの検証を行うためには、やはりデータ・サイエンティストやシチズン・データ・サイエンティストの存在が必要と言えます。
一方で、画像認識や音声認識といった視覚的、聴覚的な説明で十分なケースもあり、必ずしも専門家による結果説明が必要とされるわけではありません。学習済みモデルの利用を検討するうえでは、結果の説明責任がどの程度問われるかに注意を払うべきでしょう。
おわりに
今回は、学習済みモデルを利用したシステム/サービスの特徴と、学習済みモデルを利用する際の注意点の1つである「ユーザーのデータリテラシ(分析結果を理解し、それを説明できる能力)」について解説しました。次回は、学習済みモデルを利用する際のもう1つの注意点である「学習済みモデル開発における従来とは異なるソフトウェア開発方式や契約形態」について解説します。
関連記事
AI/機械学習とデータ分析の関係を知る(2) シチズン・データ・サイエンティストの役割
2021年9月14日 6:30
データ分析システムの全体像を理解する(8) データカタログとデータ・プレパレーション・ツール
2021年7月13日 6:30
データ分析システムの全体像を理解する(2)定型的な分析と非定型な分析
2021年1月28日 6:50
データ分析システムの全体像を理解する(3) データウェアハウスとスタースキーマ
2021年2月10日 9:13
データレイクとストリームデータ処理を理解する
2020年10月23日 6:30
DATUM STUDIOが「産学連携」と「AIのビジネス活用」をテーマに「AIアカデミックネットシンポジウム」を初開催!
2017年7月13日 0:00
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
