LifeKeeperにおける障害監視と検知
LifeKeeperにおける障害監視と検知
LifeKeeperが検出可能な障害は、ノード障害、ネットワーク障害、アプリケーションの障害、共有ディスクへのアクセス障害がある。
ノード障害の監視
ノード監視はハートビートと呼ばれるデータの定期的な交換によって相互の死活を監視している。これを行うのが表2で説明したLCMである。ハート ビートラインとして設定できるメディアはTCPとTTYである。TCPハートビートは最大98まで設定することが可能である。
TTYとはシリアルラインを指しているがTTYハートビートは2ノード間では最大1つ設定可能となっている。設定したハートビートラインは常に LCMにより相互に状態が監視されており、設定されているハートビートラインのうち1つでも不通となった場合は、GUI上のサーバアイコンが緑から黄色に 変わりオペレータに注意をうながす仕組みとなっている(図3)。

図3:ハートビートラインの監視
このハートビートラインはコミュニケーションパスとも呼ばれ、LCDI経由で更新されたサービスの状態をほかのノードのLCDに反映させるための通 信経路としても使用される。LifeKeeperにおけるノード障害はすべてのハートビートが不通となった場合を指す。
ネットワーク障害
ネットワークの監視と障害の検知は、仮想IP(IPリソース)を定義したNICに対してIPリソースの監視という形で定期的に行われる。非常にシン プルかつ確実な実装となっており、LifeKeeperにおける仮想IPの定義はLinuxのIPエイリアス機能によって実現している。
図4は図1のサーバAとサーバBに対してクライアントからのアクセスをIP-Cで行う構成例である。
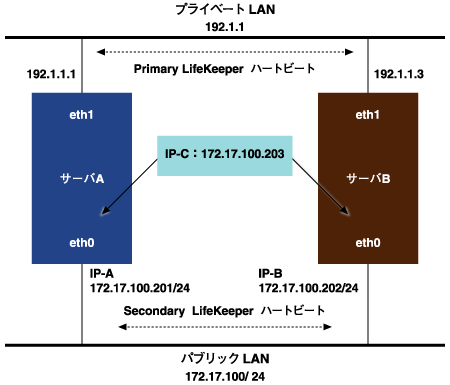
図4:クラスタ構成例
サーバAのeth0は実IP(IP-A)を持ち、サーバBのeth0は実IP(IP-B)を持っている。LifeKeeperはIPリソースをActiveとするサーバ側で以下のコマンドを実行するのである。
ifconfig eth0:1 IP-C ![]() そしてLCD内に保持しているIPリソースの情報からIP-Cが定義されているNICはサーバAのeth0とサーバBのeth0であることを得て、 定期的なリソースの監視としてIP-AとIP-B間でpingを実行するのである。この監視において相手ノードからの応答がない場合、ネットワークに対し てBroadcast pingを送出し応答があれば自ノードのNICおよびケーブルは正常でネットワークへのアクセスができていると判断する。
そしてLCD内に保持しているIPリソースの情報からIP-Cが定義されているNICはサーバAのeth0とサーバBのeth0であることを得て、 定期的なリソースの監視としてIP-AとIP-B間でpingを実行するのである。この監視において相手ノードからの応答がない場合、ネットワークに対し てBroadcast pingを送出し応答があれば自ノードのNICおよびケーブルは正常でネットワークへのアクセスができていると判断する。
アプリケーションの障害
アプリケーション(サービス)の監視はARKによって行われる。LifeKeeperはアプリケーションごとのARKが用意されており、各ARKによって監視する項目は異なる。
今回は代表的な例としてOracle ARKが行う監視を説明する。
Oracle ARKはOracle 9i SE/EE、Oracle 10g SE/SE One/EEに対応している。監視はpsコマンドでpmonの存在チェックを行うとともに、oracle管理ユーザの権限でsqlplusを起動し、以下 のコマンドを発行して実際のアクセスが可能かどうかを監視している。
connect / as sysdba
select * from dba_data_files; ![]() チェックに失敗した場合、ローカルノードでのデータベースの再起動処理が実行される。そして、再度pmonのチェックと表への問い合わせを行って起 動の確認をする。起動に失敗した場合はフェイルオーバが実行される。ローカルノードでのサービスの再起動処理をローカルリカバリと呼ぶ。ローカルリカバリ はフェイルオーバを最終手段とし、システム全体の可用性をできるだけ高めるためのポリシーで、すべてのARKは基本的にこのポリシーが組み込まれている。
チェックに失敗した場合、ローカルノードでのデータベースの再起動処理が実行される。そして、再度pmonのチェックと表への問い合わせを行って起 動の確認をする。起動に失敗した場合はフェイルオーバが実行される。ローカルノードでのサービスの再起動処理をローカルリカバリと呼ぶ。ローカルリカバリ はフェイルオーバを最終手段とし、システム全体の可用性をできるだけ高めるためのポリシーで、すべてのARKは基本的にこのポリシーが組み込まれている。
共有ディスクへのアクセス障害
共有ディスクの監視は、マウントポイント/ファイルシステム/ディスクから構成され、ファイルシステムリソースが定義されると開始される。
図5はファイルシステムリソースのリソース階層を表している。
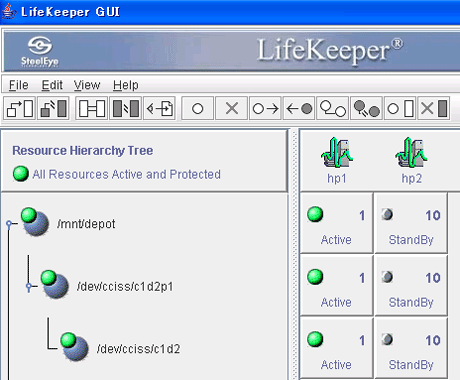
図5:リソース階層
LifeKeeperは、LUNレベルでロックするSCSI-2のReservationによりアクセス制御を実現しており、ファイルシステムリ ソースがActiveとなっているノード以外からは絶対にディスクにアクセスできない仕組みとなっている。この方式は、どんな状況においても両ノードから 同時マウントしてしまうことに起因するファイルシステムの破壊が起こらないという利点がある。
両系マウントが起きる可能性として最も多いのが、スプリットブレイン時である。quorum方式を採用しているクラスタソフトウェアの場合、タイミ ングによっては両系が同時にquorumへのアクセスが可能となりオーナーを取得してしまうことがある。また、オペレーターが誤って手動でマウントを実行 してしまう場合もある。このようなミスオペレーションもLifeKeeperは阻止することが可能である。
LUNレベルで稼動系からロックされた共有ディスクは定期的にロック状況の確認とマウント状況の確認が実行される。ロック状況の確認はSCSIレベ ルのコマンド発行により確認を行う。マウント状況の確認は、"/etc/mtab"の情報から、正しくマウントされているかや空き容量のチェックなどを 行っている。
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
