Deep Learning Lab初のエンジニア向けイベント「異常検知ナイト」レポート
実社会でディープラーニング(深層学習)の利用拡大を目的としたコミュニティ「DEEP LEARNING LAB」は異常検知に関する質問が非常に多かったことを受け、2月14日に異常検知ナイトを開催した。同コミュニティ初となるエンジニア向けのイベントで、深層学習で異常検知問題を解く方法論や異常検知関連の最新技術情報に関する情報を共有した。
2018年5月15日 16:00
実社会でディープラーニング(深層学習)の利用拡大を目的としたコミュニティ「DEEP LEARNING LAB」は異常検知に関する質問が非常に多かったことを受け、2月14日に異常検知ナイトを開催した。同コミュニティ初となるエンジニア向けのイベントで、深層学習で異常検知問題を解く方法論や異常検知関連の最新技術情報に関する情報を共有した。
2時間以上に渡るロングタイムなイベントの中から、本稿では主要なセッションのレポートをお届けする。セッション後の質問やライトニングトークなどに興味があれば、ぜひYouTubeライブのアーカイブをご覧いただきたい。
異常検知入門
最初に登壇した株式会社Preferred Networksの比戸 将平氏は、異常検知の概要を説明した。イベント当日がバレンタインデーということで、「会社でチョコを3つもらいました」「今年はチョコ0個でした」「今年も彼女が手作りどら焼きをくれました」の3つの状況を提示した。これらの状況が異常かどうか、セッションを通して明らかにしていく。

一口に異常と言っても、何によって引き起こされるのかは千差万別だ。例として、人間系では入力ミスなどのヒューマンエラーやクレジットカード不正利用などの不正行動、システム系では記憶媒体の物理故障によるシステム故障やDDos攻撃などを挙げた。また、あるトピックにおける新しい単語獲得などの質的変化も異常の1つだと紹介した。これらの異常の検出は、外れ値検出、変化点検出、異常状態検出の3つに分類できると説明し、それぞれの特徴を解説した。
外れ値検出(Outliner detection)は静的で、あるデータ点が分布から大きく外れているかをみる。変化点検出(Change point detection)は動的で、対象に変化が起きたか否か、その時点はどこかをみる。異常状態検出(Anomaly detection)も動的で、対象の状態が正常か異常かをみる。
外れ値検出は個々のデータ点の空間上の分布を考えれば良いので、統計的に扱いやすく、問題としては単純になりやすい。変化点検出と異常状態検出は時間的な変化を含んでいるため扱いが難しいが、異常検知問題のほとんどがこの2つに分類されると言う。FFT(Fast Fourier Transform、高速フーリエ変換)などの手法を用いて時系列データを多次元ベクトルに変換したり、分野依存の工夫によって時系列データをそのままモデル化して扱うことで外れ値検出問題に帰着させられるが、単純化によってデータの順序がわからなくなるなどの情報ロスが発生することも考慮しなければならないと述べた。
同氏は異常検知問題に対する典型的なアプローチとして統計ベース、ルールベース、機械学習ベースの3つを紹介した。
統計ベースはデータ母集団の形状や確率分布を仮定し、データをモデルにフィッティングする。正規分布であれば、平均と標準偏差を合わせるといった具合だ。データが仮定したモデルに従っていれば高い精度を達成できるが、一般的にデータが綺麗に分布していることは少ない。また、高次元になると単純な分布であったとしてもフィッティングが困難である。

ルールベースは既知の異常サンプルを収集し、それらを表す汎用的なルールを決めたり、学習を行う。専門家がもつドメイン知識をそのまま組み込んだり、既知の異常に良く合致するルール集合を得ることができる。一方で、背後のルールが複雑化しすぎると人間では表現できなくなったり、未知の異常に合致するルールを作ることは難しい。

機械学習ベースは教師有り異常検知と教師無し異常検知がある。教師有り異常検知では、少数の既知異常データと正常サンプルから判別する分類モデルを学習する。既知異常に大変有効である。教師無し異常検知は異常データは用いず、正常データをモデリングして異常スコアを計算するため、未知の異常にも有効だ。現在では機械学習を用いた異常検知アプローチが主流になっている。

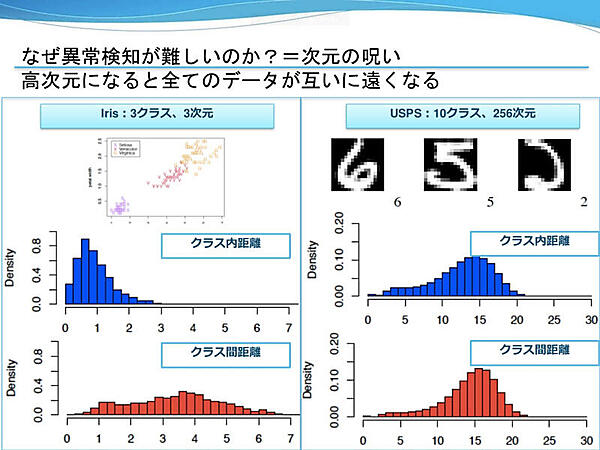
異常検知が難しいとされるのは、高次元になると全てのデータが互いに遠くなる「次元の呪い」が原因だと同氏は語る。高次元ではクラス内距離とクラス間距離の分布がおおよそ同じになってしまうため、ユークリッド距離で正常か異常かを判別するのは難しい。高次元の場合にもロバストな計算手法があるのは、他の2つにはない機械学習ベースの利点だが、データの品質で精度が左右されたり、ドメイン知識を導入するには変数の作り方を工夫するなど前処理に組み込む必要があるという。
続いて、「データサイエンティストあるある in 異常検知」と題して3つのトピックを紹介し、原因と解決策を解説した。スライドから引用したので、参考にしていただきたい。
- 見つけたい異常と見つけやすい異常が異なる
原因:異常の発生メカニズムは不問
解決策:検出後の異常分類、入力データの加工、データの絞り込みを行う - 故障そのものではなく故障の予兆を見つけたい
原因:素直にやると故障による異常度の上昇が支配的になる
解決策:異常発生前のデータに絞って、予兆らしき異常度変化があるかを見る - 異常度スコアの閾値について自動的に求めらるベストな値を求められる
原因:誤検知と見逃しによる損害の差をモデルは考慮していないため
解決策:自動化は諦める、過去の異常例からモデルを選択、運用して調整
最後に、冒頭で紹介した状況が異常かを、セッションの内容を踏まえて振り返った。まず1つ目の「会社でチョコを3つもらいました」は、会社内の平均的な個数分布から外れているかを見る「外れ値検出」が適している。「今年はチョコ0個でした」は、昨年まで何個だったかを見て今年の個数が異常なのかを判断できる「変化点検出」が良さそうだ。ここで、社会的なトレンドとしてチョコを配らなくなっているのか、個人的に特異な変動なのかなどを考慮しなければならない。「今年も彼女が手作りどら焼きをくれました」は、どら焼きがバレンタインデーのプレゼントとしてマイナーかを知るには、異常状態検出がいいだろう。
異常をどう捉えるかは主観的で、見つけたい異常を明らかにして手法を選んでいく必要があると述べた。バレンタインデーならではの変わった切り口で異常検知の概要を説明したが、初心者でも理解しやすいセッションだった。
最新異常検知ハンズオン
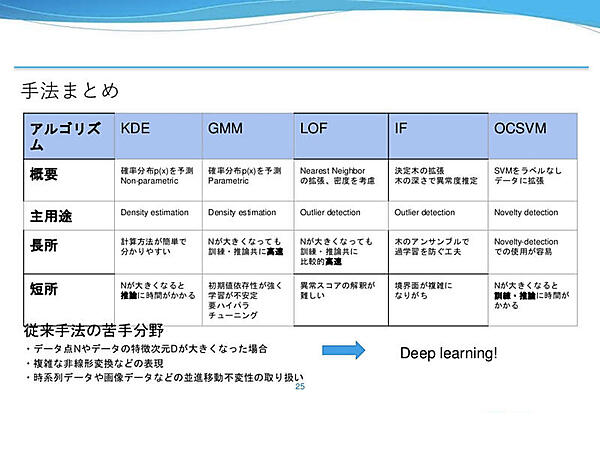
次に株式会社Preferred Networksの中郷 孝裕氏が登壇した。内容はi.i.d.データの外れ値検出のハンズオンで、Kernel Density Estimation(KDE)、Gaussian Mixture Model(GMM)、Local Outlier Factor(LOF)、Isolation Forest(IF)、One-Class Support Vector Machine(OCSVM)の5つのアルゴリズムを実装し、結果を比較した。

外れ値検出とは、全てのデータにラベル(正常 or 異常)が付与されていない中で、特に振る舞いの異なる点を探すことである。白丸の正常データ150点、黒丸の外れ値データ50点のデータセットを使用する。正常データは(-2, -2)または(2, 2)付近にGaussian noiseを加えて生成したもの。外れ値データは[-7, 7]の空間全体に一様に分布している。
Kernel Density Estimationは各データ点xiにKernelを重ねてデータ分布p(x)を表現し、データの存在確率p(x)が低いところを異常値として考える。Hyper parametersはbandwidthで、足し合わせるGaussianの標準偏差の値だ。結果を見ると、bandwidthが大きくなるに従ってGaussianの幅が広がり、予測分布p(x)がなだらかになっていることがわかる。

Gaussian Mixture Modelはデータ分布p(x)をn個のGaussianの線形和の近似で表現する。パラメータの最尤推定値はEMアルゴリズム(expectation–maximization algorithm)で求める。データの存在確率p(x)が低いところを異常値として考えるのはKDEと同様だが、テータ点数Nが多い場合でもKDEより高速に推論できるのが特徴だ。主要なHyper parametersのn_componetsは足し合わせるGaussian数で、この値によって結果が大きく異なる。n_componetsが小さいほど予測分布p(x)がなだらかになる。

Local Outlier FactorはNearest Neighbor法を拡張したような手法で、周辺のデータとの局所的な関係から異常度を計算する。距離ベースの異常値計算手法との大きな違いは、周辺データの密集度を考慮する点だ。Hyper parametersのn_neighborは、いくつのNearest Neighborまでを考慮するかを決めるもので、大きいほど緩やかな決定境界面を構成する。contaminationはどの割合のデータまで外れ値にするか、閾値決定に影響するもので、今回のハンズオンでは0.25に固定されている。

Isolation Forestは決定木(Decision Tree)を拡張した手法だ。木を構築する時、分割する特徴量や値はランダムに決める。外れ値は正常値と比較して少ない条件で分離できるというのが基本アイデアで、深さをスコアとすれば浅い部分で分割されたノードは異常度が高い。Hyper parametersは3つ。n_estimationは作成する弱学習器の数、max_samplesは各木の学習に用いるデータの個数、contaminationはどの割合のデータまで外れ値にするかを示す。n_estimationとmax_samplesが多いほど挙動が安定しやすい一方で、学習に要する時間は増加する。

One-Class SVMはSVMを改変した手法である。SVMは一般的にラベル付きのデータを2クラスに分類する境界面を探すが、OCSVMは(1-ρ)のサンプルを最小の体積に押し込める境界面を探す。適切なカーネル関数を設計することで、様々なデータに対応できるのがメリットだ。主要なHyper parametersは、どの割合のデータまで外れ値にするかを示すnu、使用するカーネルの係数に対応するgammaだ。nuが大きいほど外れ値に対してロバストになる。すなわち、細かいデータ分布を無視するようになる。gammaはrbf kernelの場合、大きくなるほどより細かな挙動を捉えられる。

5つの外れ値検出結果を比較すると、今回のような簡単なデータセットではほとんど差は出なかった。しかし、それぞれのアルゴリズムの主な用途、長所、短所は異なる。中郷氏は「適用する問題に応じて、適宜試してみると良いのではないか」と述べた。
時系列データのリアルタイム異常検知
続いて登壇した株式会社Preferred Networksの小松 智希氏は最初に時系列データの異常検知の例として工場機器の故障予測や攻撃検知などを挙げ、需要の高さを説明した。セッションでは特定のパターンで動作するマシンの異常を想定し、畳み込みニューラルネットワーク(CNN)による異常検知を行う。

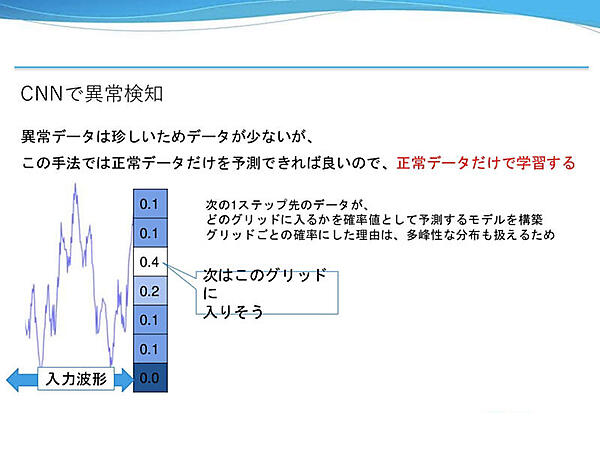
時系列データに対するアプローチとしては、自己回帰モデルによる異常検知が有名だという。時系列データの直前のN点をみて次にとる点を予測するといったもので、直前のN点で線形回帰するだけの非常に簡単な手法だ。もし、予測値と実測値の差(予測誤差)が大きければ、何か異常が起こっていると判断できる。しかし、線形回帰は表現力が弱く、非線形な要素が強い波形に対して適用するのは難しいので、CNNに置き換える。
一般的に異常データは正常データより少ないが、今回の手法では正常データだけを予測できればい良いので、正常データのみを学習データとする。学習データに含まれていないデータは予測できないことを利用すれば、予測の外れ具合を異常度として扱うことができる。次点のデータが取り得る領域をグリッドで分割し、どのグリッドに入るかを確率値として予測するモデルを構築した。グリットで分割した理由は、多峰性な分布も扱えるようにするためだと説明した。
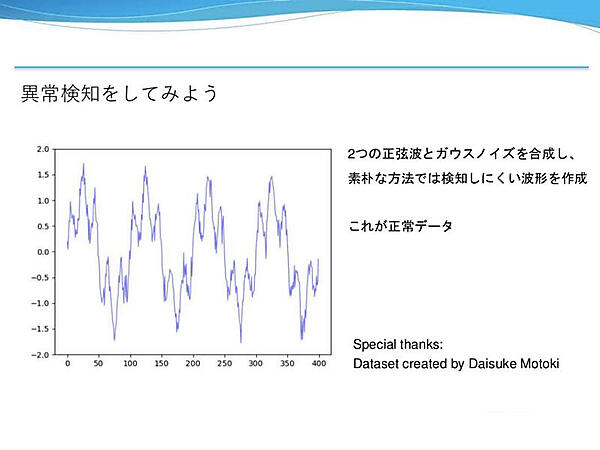
2つの正弦波とガウスノイズを合成した波形を正常データとして使用する。ある程度複雑な波形なので、素朴な手法では検知しにくいという。
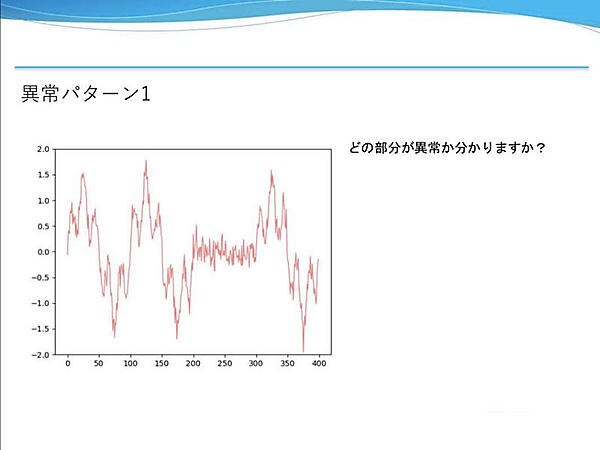
異常パターン1は、周期的な波形のある区間だけガウスノイズだけの波形が出現している。先ほどの正常データと見比べるとわかりやすい。
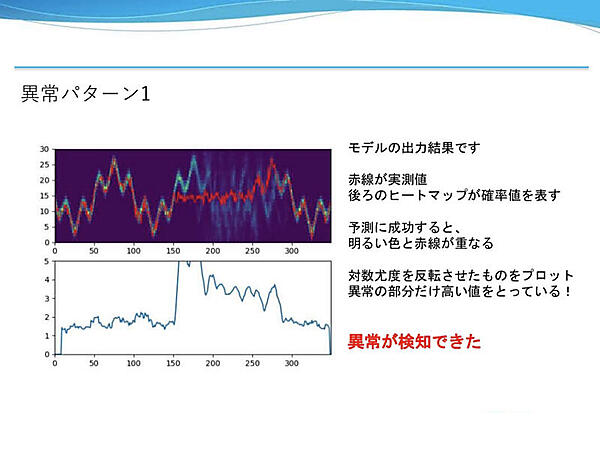
上図のモデルの出力結果において、確率値を表すヒートマップと実測値(赤線)が重なっている部分は予測に成功、ズレが生じている部分は予測に失敗している。下図は実測値が通ったところの確率値の対数尤度を反転させてプロットしたグラフだ。予測に失敗した部分だけ高い値をとっているので、異常が検知できたと言える。
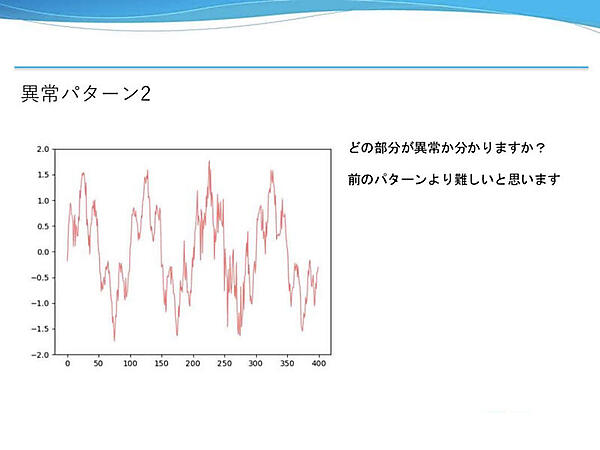
異常パターン2は正常データと同様に2つの正弦波とガウスノイズを合成した波形だ。一見したところほとんど違いが無いようだが、ある区間だけガウスノイズの分散が大きくなっている。
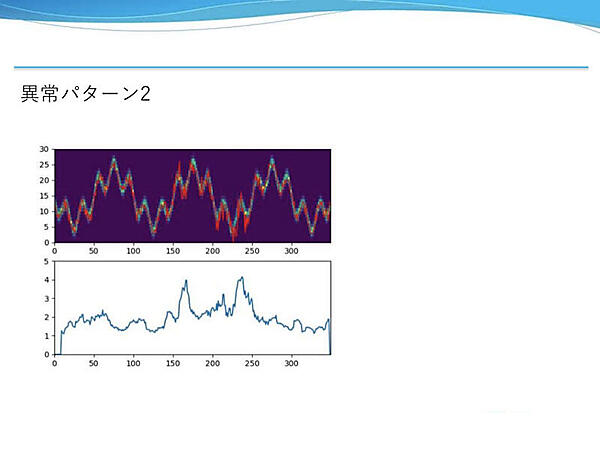
モデルの出力結果では、予測値のヒートマップと実測値が乱れずほとんど重なっているように見える。しかし、異常度のグラフでは、ガウスノイズの分散が大きい部分で予測が外れて異常度が高くなっている。これは適切な閾値を設定すれば異常を検知できる例だと述べた。
異常パターン3は、含まれる周波数成分が少し違う。僅かな差ではあるが、周期的な正常データと比較するとある区間で波形が異なる。
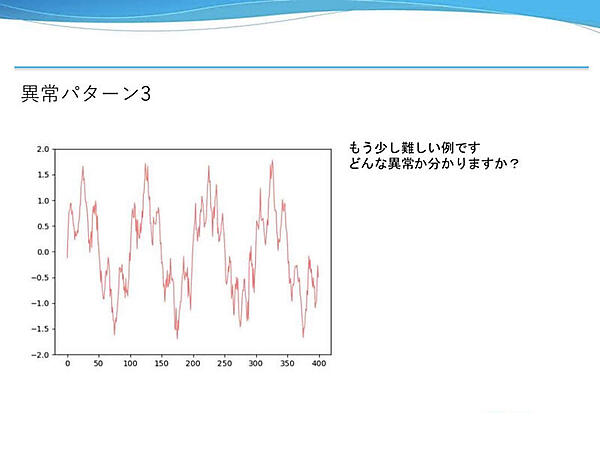
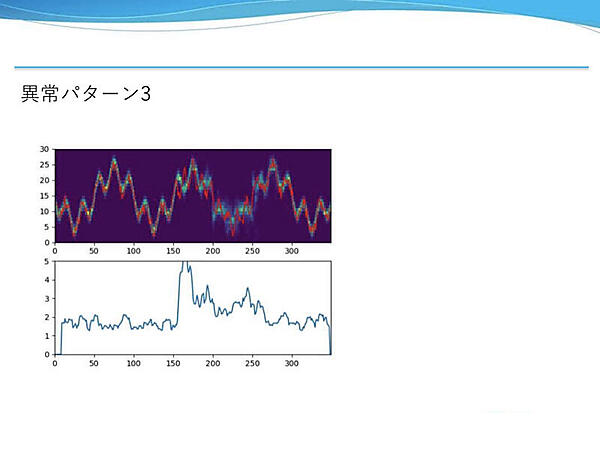
モデルの出力結果を見ると、周波数成分が異なる部分で予測に失敗している。この予測値のヒートマップと実測値にズレが生じたところで異常度が上がっている。前例と同様に僅かな異常だったが、検知に成功した。
以上の例を見て気づいた読者もいると思うが、正常パターンの波形は周期性があるので、実測値の波形との差分をとれば異常を検知できそうだ。小松氏は「この例では確かに可能だが、もっと複雑で難しいケースを考えてみてほしい」と述べ、パターンマッチでは検知が困難な例の紹介に移った。
簡単な例題として、複数チャネルの相関異常検知問題を紹介した。各々固有の動作をするモード1と0があるマシンで、動作モードを命令するタイミング不定のパルス波がある。マシンが命令に従っているかを監視したいといったものだ。
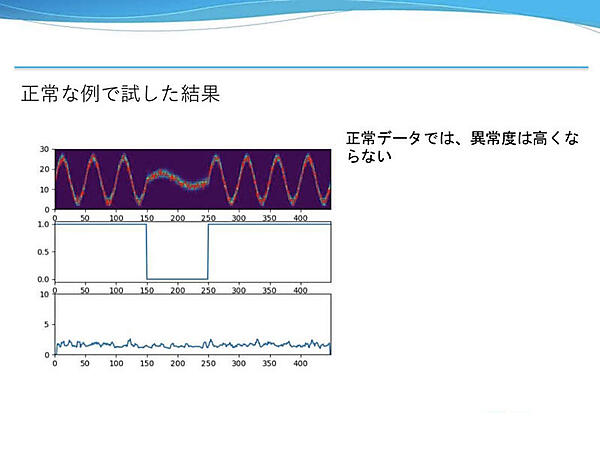
上のグラフがモデルの出力結果とセンサー値(赤線)、中央のグラフが動作モード、下のグラフが異常度を表している。モード1は高周波で振幅が大きいのに対し、モード0は低周波で振幅が小さい。正常な例では安定して異常度が低い結果となった。
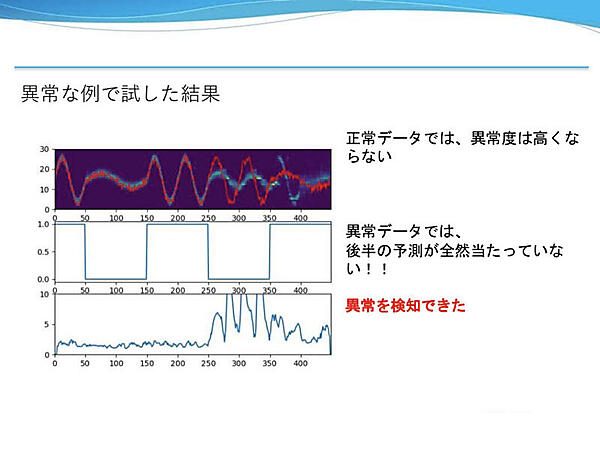
異常な例のポイントは、センサー値と動作モードのグラフを個別に見るとなんら異常はないが、同時に見ると適切にモードが切り替わっていない区間があることだ。後半、モード0の命令でモード1の波形を計測している部分で異常度が高くなっており、異常を検知できた。
小松氏によるとCNNを使った異常検知、特に相関異常を検知する需要は多いという。今回は恣意的な例が多かったが、例えば外気温センサーと監視マシンの背温度センサーをみて、外気温が低いのにマシンの温度が高いといったようなマシンの熱暴走の監視などに有用なので試してほしいと話した。
- 画像異常検知ソリューション「gLupe」の裏側
- ALBERTにおける異常検知ケーススタディ
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Deep Learning Lab初のエンジニア向けイベント「異常検知ナイト」レポート
2018年5月15日 16:00
Azure+クラウド型電子カルテにおけるリソース利用効率の課題と改善への道すじ
2019年6月13日 6:00
SIの労働生産性を高めるIaCとは?ITエンジニアのためのコミュニティ「IaC活用研究会」キックオフイベントレポート
2018年4月12日 18:40
話題のDockerの魅力とは? OSSインフラナイター vol.1 レポート
2017年7月14日 0:15
ITエンジニア必見の夏の祭典「July Tech Festa 2018」レポート
2018年10月25日 6:00
「FFXV」に活かされたAIとは?「Pokémon GO」に続くARゲームの登場も間近か…日々進化するゲーム業界のAI・ARに迫る
2017年12月5日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
